AI模型
AI 模型
注意
目前仅「BGI-华北2」片区上线 AI模型 功能。
产品简介
整体介绍
DCS AI 模型面向生物信息模型开发者,提供了从开发、训练、微调、部署、发布、调用的全链路解决方案。 无论您是需要探索生命科学的垂类模型(如 Genos),还是自然语言的通用大模型(如 Qwen, DeepSeek 等),我们都能提供统一的高效管理体验。让复杂的 AI 资产变成触手可及的标准 API,赋能企业智能化创新。
核心优势
多模态模型兼容: 统一纳管 Qwen/DeepSeek 等通用大模型及 Genos 等生物序列模型。
无缝的微调体验: 提供开箱即用的 Notebook 在线开发空间,预置主流深度学习框架与微调依赖。支持用户直接通过代码进行高效微调(如 LoRA),省去繁琐的环境配置,让您专注于模型效果的优化。
标准化服务交付: 无论底层使用 PyTorch、TensorFlow 还是 vLLM,对外均暴露标准化的 API 接口,降低下游集成成本。
常用概念
模型: 静态的算法资产,包含模型文件、权重及元数据。
服务: 模型运行时的实例。将静态模型加载到计算资源上,对外提供 API 调用能力。
部署: 将模型转化为服务的动作,涉及资源分配、镜像选择和启动命令配置。
微调: 基于基座模型,使用特定数据集进行再训练,以提升模型在特定领域的表现。
推理: 调用模型服务进行预测或生成内容的过程。
快速入门:算法工程师篇
本文主要面向有一定编码能力的算法工程师。在首次使用 DCS Cloud 的情况下,帮助用户快速上手,体验使用产品进行模型创建、微调、部署、发布。主要适用场景:
- 模型已经训练完成,用户需要在对代码零修改的情况下,将相关工作迁移到 DCS Cloud,利用其提供的 GPU & CPU 算力、数据存储和Notebook 在线开发空间等能力完成模型的高效迭代。
环境准备
在开始之前,请确保您已在「镜像管理」中构建或选择了包含所需依赖(如 vLLM, PyTorch)的镜像。镜像将用于部署模型、模型微调和模型推理。
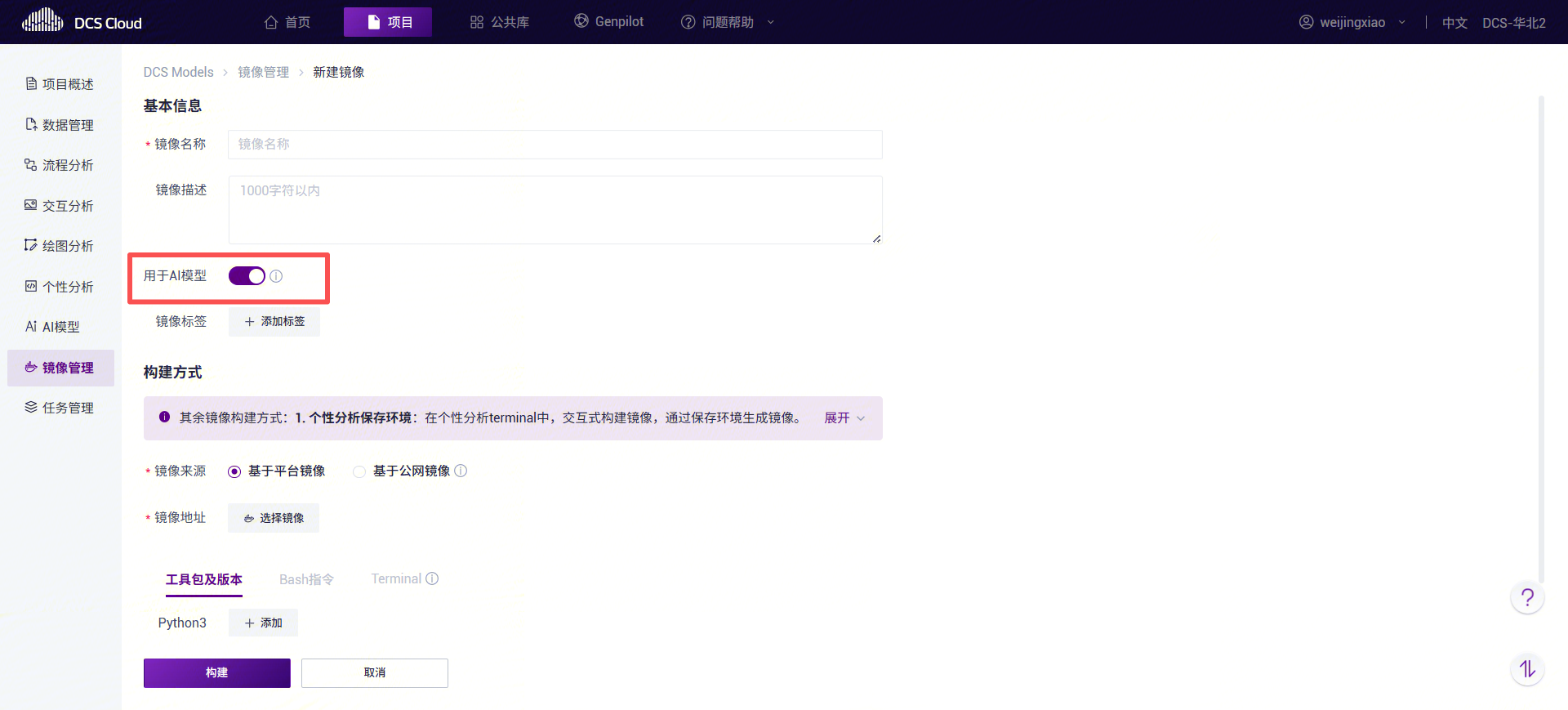
注意
用于模型部署的镜像,构建时需要将“用于 AI 模型”开关打开。
数据上传
通过项目「数据管理」上传模型文件,DCS智能云平台提供了多种数据上传方案。详见添加文件。
模型创建
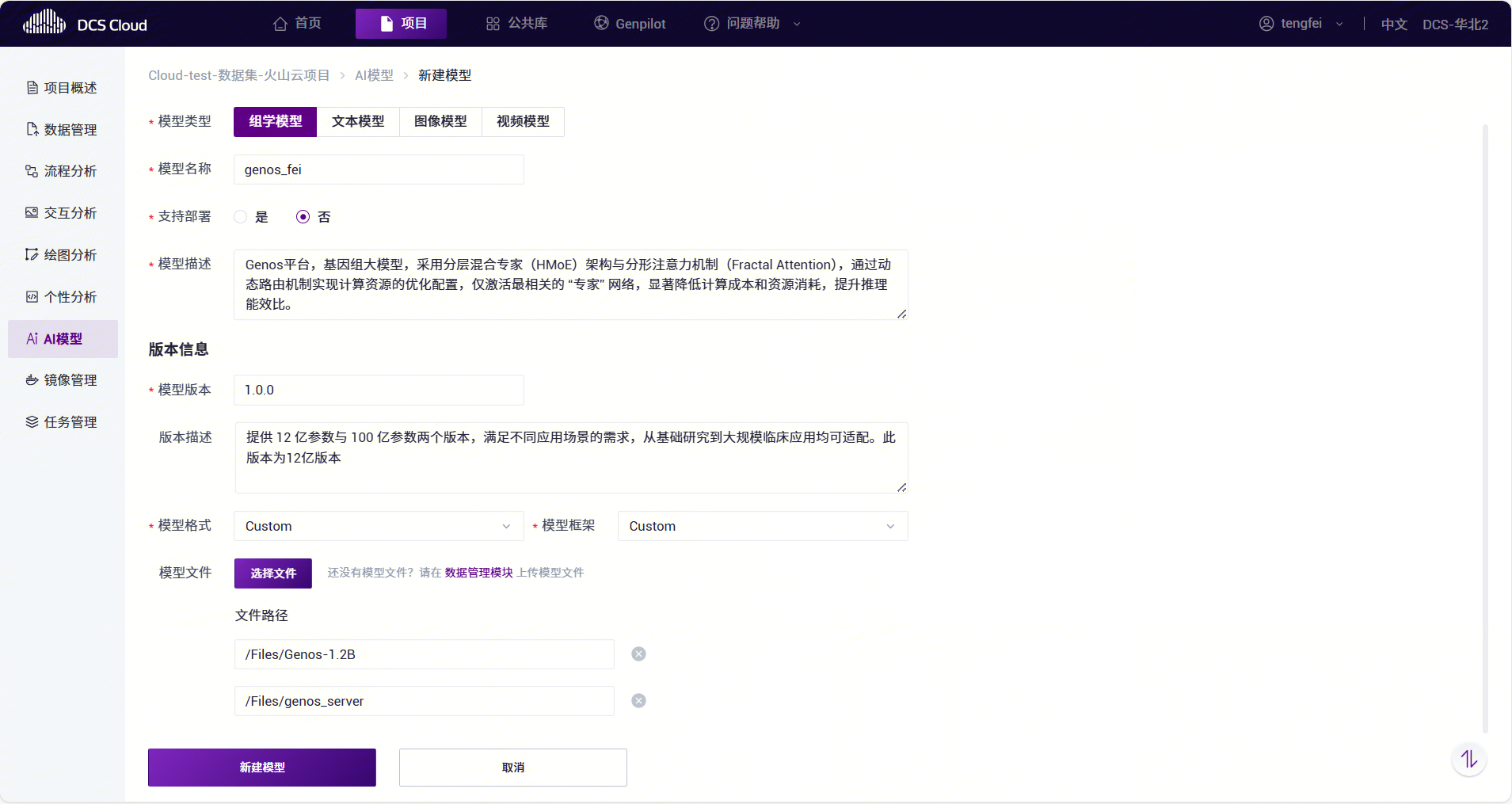
进入 项目 -> AI模型 模块,点击右上角的【新建模型】按钮。
在 新建模型 页面填写基础信息:
参数名称必填参数说明 模型类型 是 选择模型的类型,支持“组学模型”、“文本模型”、“图像模型”、“视频模型”。 模型名称 是 填写模型的名称。 支持部署 是 模型是否支持部署成服务。若该模型需对外提供 API,务必选择“是”。 模型描述 否 填写对模型的适当描述。 模型版本 是 填写对模型的版本信息。 版本描述 否 填写对模型版本的适当描述。 模型格式 是 选择模型的格式。支持 SavedModel、TorchScript、ONNX 等多种模型格式。 模型框架 是 选择模型的训练框架及版本。 支持 TensorFlow、PyTorch、XGBoost 等多种框架和版本。 模型文件 是 从数据管理模块选择已上传的模型文件。 点击【新建模型】完成新建。
模型复制
若您暂无模型资产,您可以前往公共库直接查找平台预置优质基座模型,DCS Cloud 公共库预置了业界主流的通用大模型以及平台专属的生物计算模型(如 Genos 系列)。您可以通过“复制”功能,一键将这些只读的公共资产“复制”到项目中,将其转化为可微调、可部署的私有资产。
模型推理-个性分析
模型完成创建后, 未部署成服务之前,您可以通过 Notebook 在线开发环境 直接加载模型权重进行推理。
在模型卡片或者详情页,点击【推理】按钮。
环境配置:
计算资源: 选择运行资源。
运行镜像: 选择运行镜像。
点击【启动】,开始启动个性分析完成。
提示
DCS Cloud 已默认将模型文件挂载到容器中。
您也可以在模型部署完成后再通过标准的 HTTP API 接口在任何网络环境下进行推理调用,无需再依赖 Notebook 环境。
模型微调
DCS Cloud 提供了 Notebook 在线开发空间,用户可直接使用「个性分析」完成模型的微调:
回到「AI 模型」模块,在模型卡片或模型详情页,点击【微调】按钮。
环境配置:
计算资源: 选择运行资源。
运行镜像: 选择运行镜像。
点击【启动】,开始启动个性分析完成。
提示
DCS Cloud 已默认将模型文件挂载到容器中,您可以在容器中通过【重置资源】挂载特定的领域数据
- 模型微调完成后,产出的新权重文件可保存至「数据管理」,再通过【新建模型】创建新的模型。保存数据参考 个性分析-保存数据。
模型部署
调优后的模型,通过部署可获得独立的、资源专享的服务。
在模型列表中找到目标模型,点击卡片上的【部署】按钮。
部署模型 需要完成部署配置、调用示例、费用配置三个步骤:
部署配置,基础信息如下:
参数名称必填参数说明 部署名称 是 填写服务的名称。 镜像 是 选择部署的镜像。 服务端口 是 支持部署中新增自定义调用端口,调用端口限制范围:1-65535。 路径 否 配置服务对外暴露的API路由。若填写 /v1,则部署成功后通过 https://cloud.stomics.tech/api/aigress/openai/v1 访问服务。 计算资源 是 选择运行部署的计算资源。 数据挂载 否 支持选择数据管理的文件挂载到实例中。 输出路径 否 自定义写入路径,容器内产生的需要持久化的数据将写入此路径,如不需要写入数据则留空。 运行命令 是 部署服务的启动命令。 环境变量 否 将被注入到容器实例中的环境变量。 调用示例,提供完整准确的调用示例才能保证模型调用者正常访问服务。平台为您自动生成了基于 cURL 的标准调用代码,生成规则如下:
Endpoint 生成: 拼接格式为
{平台统一网关地址} + {配置的服务路径}。例如:若您在“部署配置”步骤的“路径”字段填写了/v1,则调用地址自动更新为https://cloud.stomics.tech/api/aigress/openai/v1。参数配置:
-d参数中的modelID 已自动关联当前服务。自定义参数: 您仅需在
model字段后,添加模型特定的输入参数说明(例如生物序列sequence或超参max_tokens)。
curl -X POST "https://cloud.stomics.tech/api/aigress/openai/" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR_API_KEY>" \
-d '{
"model": "genos_2",
# Add additional custom parameters here, e.g.,
# "sequence": "ATCGATAAAAATTTCG",
# "temperature":0.6,
# "max_tokens": 1024
}'
费用配置,设置该模型服务的计费标准:
输入定价:用户发送的提示词(Prompt)所消耗的 Token。通常包含问题描述、上下文及指令。
输出定价:模型生成的内容(Completion)所消耗的 Token。由于推理生成计算量更大,建议定价高于输入。
缓存定价:命中上下文缓存(Context Cache)的输入 Token。当用户发送重复的长文本(如文档问答)时触发,通常定价应显著低于普通输入,以鼓励长上下文复用。
确认无误后点击【确认部署】开始部署服务,服务部署的状态信息可在项目「任务管理-模型服务」中查看。
接口调试
在项目「任务管理-模型服务」中查看任务状态。待服务部署成功后(状态变为运行中):
点击任务操作栏的 服务调用 。
复制
curl命令到本地终端或使用 Postman 进行测试。
模型发布
模型发布是将您项目中的私有模型资产共享至 DCS Cloud 公共库 的过程。发布后的模型将获得全局唯一的公共 ID,其他用户可直接通过 API 示例调用模型能力,也可以将其复制到项目中进行推理和微调。
快速入门:应用开发者
本文主要面向负责业务逻辑集成与开发的后端/全栈工程师。在首次使用 DCS Cloud 的情况下,帮助用户快速上手,体验模型发现、API Key 获取、服务调用的全流程。主要适用场景:
模型已由算法团队发布为在线服务,开发者需要在无需关注底层 GPU 资源与模型推理细节的情况下,将 AI 能力(如 Genos 生物计算或通用 LLM)快速接入现有业务系统。利用 DCS Cloud 提供的统一标准 API,实现 AI 能力的即插即用与稳定生产。
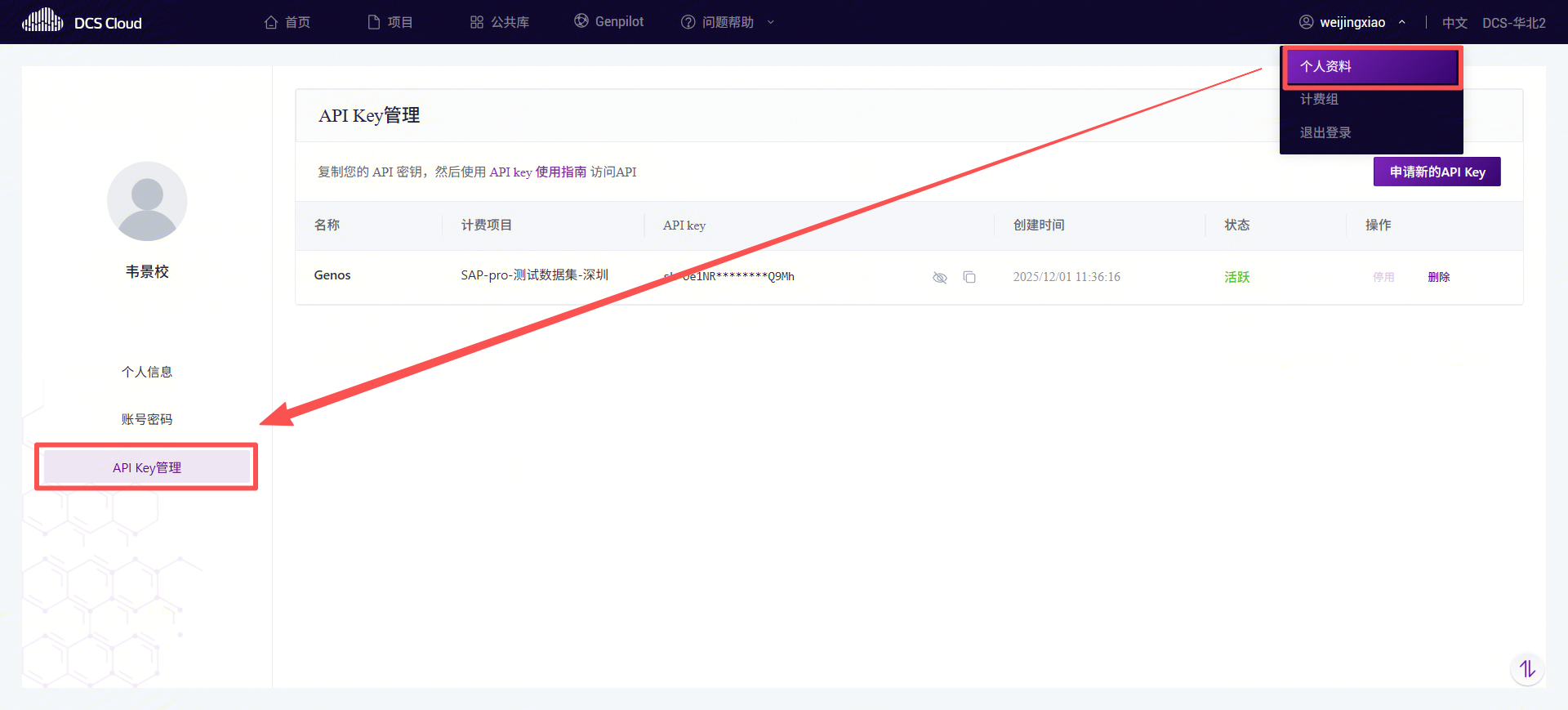
API Key 获取
API Key 是您访问 DCS Cloud 模型服务的唯一身份凭证。平台通过 API Key 识别您的身份并进行权限验证与计费统计。
您可以在「个人中心」创建个人的 API Key。并复制生成的 API Key。
模型发现
公共库-模型广场是 DCS Cloud 提供的官方 AI 资产仓库。这里汇集了业界最前沿的通用大语言模型(如 DeepSeek, Qwen, Llama 系列)以及平台独有的垂直领域生物计算模型(如 Genos)。用户可直接通过 API 调用,也可以复制至项目中进行微调。您可以在公共库查找感兴趣的模型:
访问 公共库 -> 模型广场。
通过顶部标签(如“组学模型”、“文本模型”)筛选感兴趣的模型。
点击模型卡片进入 模型详情页。
在详情页查阅模型 计费说明,确认推理价格。
集成调用
在公共库模型详情页的 API 示例 标签中,可以复制调用代码。
用户指南
用户指南其中包含各模块中重要功能的使用方法以及限制的详细介绍。
新建模型
概述
用于将离线的模型文件注册到平台资产库中,以便后续进行部署、微调、推理或发布。
使用步骤
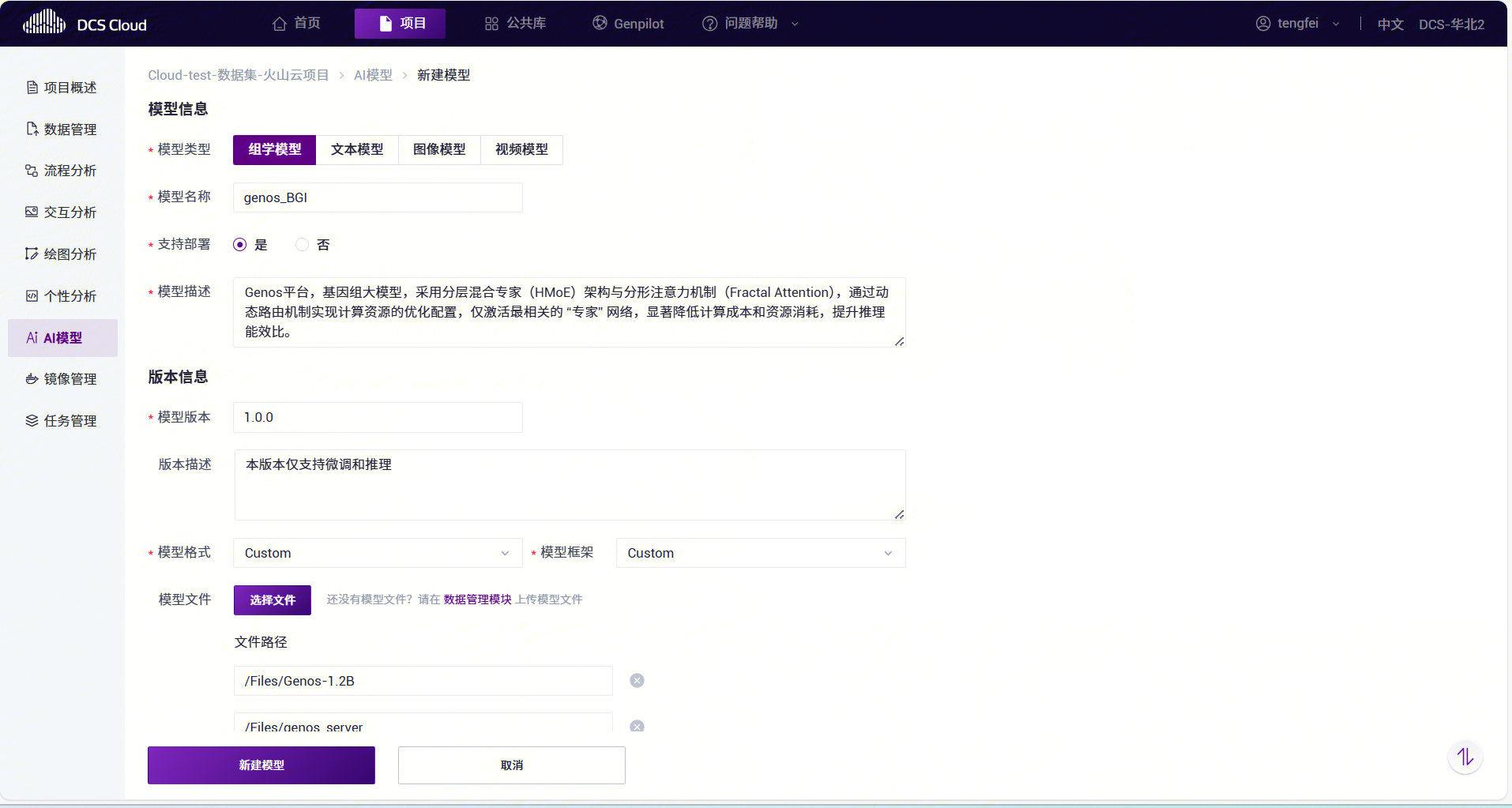
进入 项目 -> AI模型 模块,点击右上角的【新建模型】按钮。
在 新建模型 页面填写基础信息:
参数名称必填参数说明 模型类型 是 选择模型的类型,支持“组学模型”、“文本模型”、“图像模型”、“视频模型”。 模型名称 是 填写模型的名称。 支持部署 是 模型是否支持部署成服务。若该模型需对外提供 API,务必选择“是”。 模型描述 否 填写对模型的适当描述。 模型版本 是 填写对模型的版本信息。 版本描述 否 填写对模型版本的适当描述。 模型格式 是 选择模型的格式。支持 SavedModel、TorchScript、ONNX 等多种模型格式。 模型框架 是 选择模型的训练框架及版本。 支持 TensorFlow、PyTorch、XGBoost 等多种框架和版本。 模型文件 是 从数据管理模块选择已上传的模型文件。 点击【新建模型】完成新建。
模型部署
概述
模型部署是将静态的模型资产(如 .safetensors, .pt 权重文件)转化为动态在线服务的过程。系统通过容器化技术加载模型,并将其封装为标准的 HTTP API 接口,从而为业务应用提供高可用、低延迟的实时推理能力。
使用步骤
调优后的模型,通过部署可获得独立的、资源专享的服务。
在模型列表中找到目标模型,点击卡片上的【部署】按钮。
部署模型 需要完成部署配置、调用示例、费用配置三个步骤:
部署配置,基础信息如下:
参数名称必填参数说明 部署名称 是 填写服务的名称。 镜像 是 选择部署的镜像。 服务端口 是 支持部署中新增自定义调用端口,调用端口限制范围:1-65535。 路径 否 配置服务对外暴露的API路由。若填写 /v1,则部署成功后通过 https://cloud.stomics.tech/api/aigress/openai/v1 访问服务。 计算资源 是 选择运行部署的计算资源。 数据挂载 否 支持选择数据管理的文件挂载到实例中。 输出路径 否 自定义写入路径,容器内产生的需要持久化的数据将写入此路径,如不需要写入数据则留空。 运行命令 是 部署服务的启动命令。 环境变量 否 将被注入到容器实例中的环境变量。 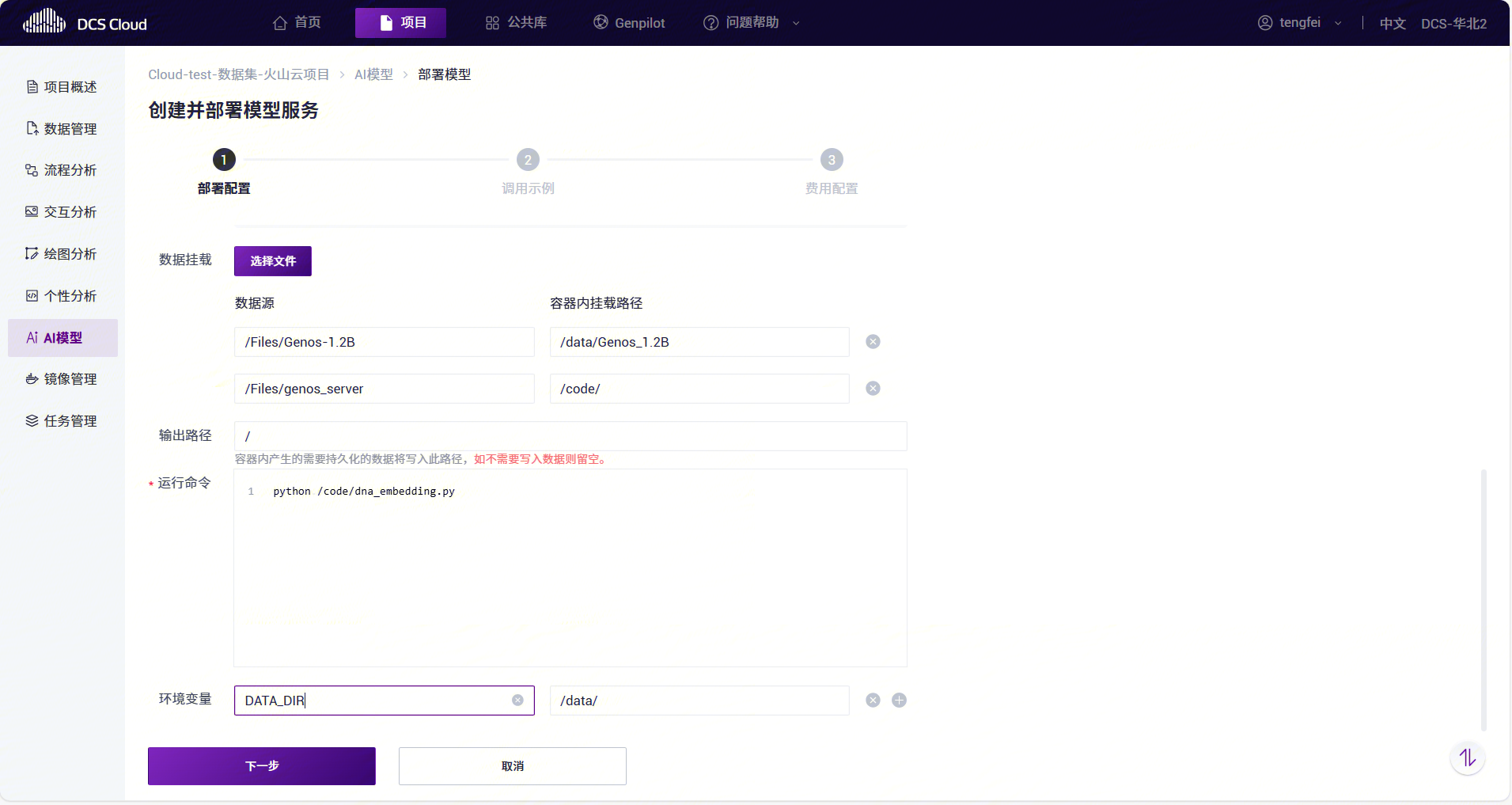
注意
执行服务脚本时,脚本路径应为容器内部挂载后的路径。 例如:源文件 /files/dna_embedding.py 挂载到容器内 /code/dna_embedding.py,则执行命令如下:
python /code/dna_embedding.py <your_script_args>返回结构规范 服务脚本需返回一个 JSON 对象,其中:
- usage.prompt_tokens — 输入 token 数,用于计费 (必填)
- usage.completion_tokens — 输出 token 数,用于计费 (必填)
其余字段可根据服务需求自定义返回。
返回结构示例
return json({ "usage": { "prompt_tokens": len(sequence), "completion_tokens": model_token, }, "status": 200, "message": "客户端序列 embedding 提取成功", "result": result, })调用示例,提供完整准确的调用示例才能保证模型调用者正常访问服务。平台为您自动生成了基于 cURL 的标准调用代码,生成规则如下:
Endpoint 生成: 拼接格式为
{平台统一网关地址} + {配置的服务路径}。例如:若您在“部署配置”步骤的“路径”字段填写了/v1,则调用地址自动更新为https://cloud.stomics.tech/api/aigress/openai/v1。参数配置:
-d参数中的modelID 已自动关联当前服务。自定义参数: 您仅需在
model字段后,添加模型特定的输入参数说明(例如生物序列sequence或超参max_tokens)。
curl -X POST "https://cloud.stomics.tech/api/aigress/openai/" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR_API_KEY>" \
-d '{
"model": "genos_2",
# Add additional custom parameters here, e.g.,
# "sequence": "ATCGATAAAAATTTCG",
# "temperature":0.6,
# "max_tokens": 1024
}'
费用配置,设置该模型服务的计费标准:
输入定价:用户发送的提示词(Prompt)所消耗的 Token。通常包含问题描述、上下文及指令。
输出定价:模型生成的内容(Completion)所消耗的 Token。由于推理生成计算量更大,建议定价高于输入。
缓存定价:命中上下文缓存(Context Cache)的输入 Token。当用户发送重复的长文本(如文档问答)时触发,通常定价应显著低于普通输入,以鼓励长上下文复用。
确认无误后点击【确认部署】开始部署服务,服务部署的状态信息可在项目「任务管理-模型服务」中查看。
模型微调
概述
模型微调是基于预训练的基座模型,使用特定的领域数据进行二次训练,以提升模型在特定任务上的表现。DCS Cloud 提供了 Notebook 在线开发空间,用户可直接使用「个性分析」完成模型的微调:
使用步骤
在模型详情页或列表页,点击【微调】按钮。
环境配置:
计算资源: 选择运行资源。
运行镜像: 选择运行镜像。
点击【启动】,开始启动个性分析完成。
提示
DCS Cloud 已默认将模型文件挂载到容器中,您可以在容器中通过【重置资源】挂载特定的领域数据
- 模型微调完成后,产出的新权重文件可保存至「数据管理」,再通过【新建模型】创建新的模型。保存数据参考 个性分析-保存数据。
模型推理
模型推理是指利用训练好的模型,对输入数据进行计算并生成输出结果的过程。无论是生成一段文本、预测一段 DNA 序列的功能,还是分类一张图片,都属于推理。模型推理步骤:
在模型卡片或者详情页,点击【推理】按钮。
环境配置:
计算资源: 选择运行资源。
运行镜像: 选择运行镜像。
点击【启动】,启动个性分析完成模型推理。
提示
DCS Cloud 已默认将模型文件挂载到容器中。
任务管理 - 模型服务
概述
用于集中监控和管理项目内所有已部署的推理服务实例。用户可在此查看服务状态、获取调用地址、以及对服务进行启停或释放操作。
使用步骤
状态监控:在列表中查看所有服务的当前状态(如 Running, Pending, Stopped)。
服务筛选:使用搜索框或状态下拉菜单过滤特定服务。
获取调用方式:点击列表中的 【服务调用】 按钮,系统将弹出包含
cURL代码的窗口,支持一键复制,用于快速测试服务连通性。生命周期管理:
停止/启动:点击【更多】图标,选择停止以释放 GPU 资源(停止后不再计费),或重新启动服务。
删除:彻底释放服务资源及配置。
状态说明表
| 状态 | 说明 |
|---|---|
| 未运行 | 部署被停止后,部署实例被清空。 |
| 部署中 | 节点调度、镜像拉取、启动实例的阶段。 |
| 队列中 | 资源满了需要排队。 |
| 运行中 | 实例正在运行中,正常对外提供服务。 |
| 异常 | 实例部署超时或者运行过程中出错。 |
模型广场
概述
模型广场是 DCS Cloud 的核心资产发现中心,汇集了官方发布的 SOTA 模型(如 Qwen, Llama)以及企业内部沉淀的私有模型。用户可在此快速检索、体验并获取模型的调用方式。
使用步骤
筛选与检索:通过顶部的标签栏(全部/组学/文本/图片/视频)快速过滤模型类型,或使用搜索框输入关键词查找。
查看详情:点击模型卡片进入详情页,查看模型的架构说明、上下文窗口大小、计费标准及 API 调用示例。
收藏与互动:点击卡片底部的【收藏】(星形图标)将常用模型加入收藏夹,或通过【点赞】反馈模型质量。
获取代码:在详情页的“API 示例”标签中,直接复制 cURL 或 Python 代码用于业务集成。