scVDJ
scVDJ-seq中文用户手册
第一章 应用范围
单细胞免疫组库分析流程(以下简称scVDJ-seq)是用于研究单个免疫细胞的基因表达和免疫反应的技术。可以处理以下试剂盒的高通量测序数据分析:
DNBelab C系列高通量单细胞5'RNA&V(D)J文库制备试剂盒套装。
第二章 产品介绍
2.1 分析流程图
scVDJ-seq分析流程是基于DCS云平台系统开发的一款自动分析流程,其中包括5端RNA分析,数据质控,VDJ文库reads提取,从头组装与注释,有效细胞筛选,克隆型鉴定以及报告生成:
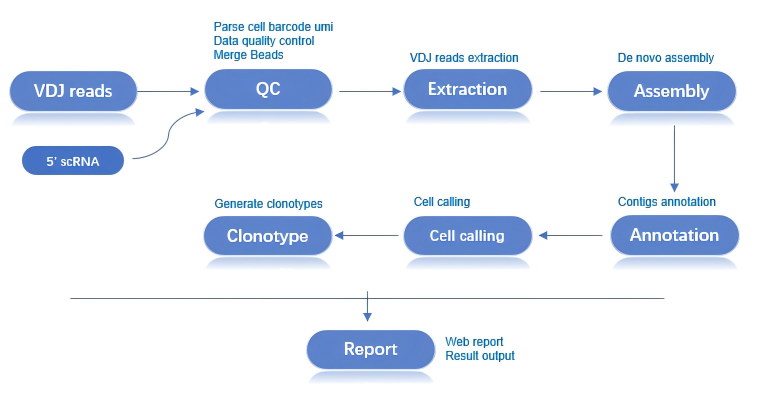
2.1.1 5端RNA分析
与scRNA-seq_v3分析内容相同,区别仅在于scRNA-seq_v3从3端分析,scVDJ-seq从5端分析,找到细胞和磁珠的对应关系。
2.1.2 数据质控
通过识别细胞条形码和细胞的对应关系,经过数据质控和合并磁珠,将测序数据分离为单个细胞。
2.1.3 获取 VDJ 区域序列
使用TRUST4将每个细胞的RNA数据与VDJ基因的参考序列进行比对,提取VDJ区域序列。
2.1.4 VDJ从头组装和文库注释
使用TRUST4对每个细胞的VDJ区域进行从头组装和文库注释。
2.1.5 有效细胞筛选和克隆型鉴定
根据VDJ组装注释结果和 5端转录组的细胞获取情况进行细胞过滤,获取的有效细胞进行克隆型鉴定。
2.1.6 报告生成
综合分析结果,整理汇总成HTML报告。
第三章 使用说明书
scVDJ-seq分析流程通过DCS云平台系统进行样本输入及报告输出的全流程管理。下面具体介绍基于DCS云平台系统使用scVDJ-seq分析流程的操作指南。
3.1 概述
本章介绍如何使用scVDJ-seq分析流程进行分析。在使用之前,请认真阅读并理解其中内容,保证能够正确使用scVDJ-seq分析流程。
3.2 使用场景一:手动投递
操作共包括四个步骤:上传数据、构建参考基因组(可选)、样本信息录入、启动分析。完成样本信息录入后,运行任务,当客户在看到任务状态为![]() completed 时,代表任务已完成,即可查看报告部分(详见3.4部分)。
completed 时,代表任务已完成,即可查看报告部分(详见3.4部分)。
3.2.1 步骤一:上传数据
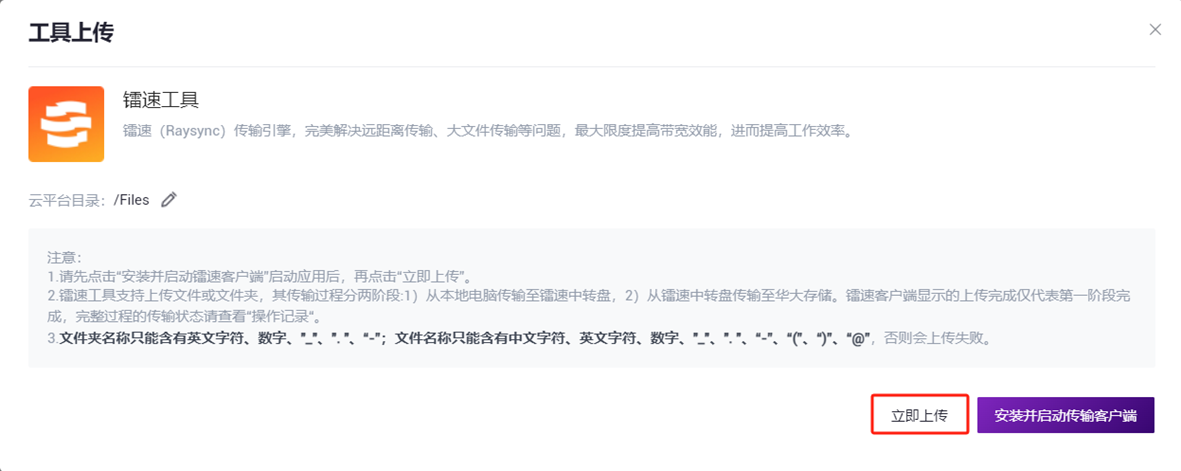
点击导航栏【Data】,进入数据管理页面,进入目标文件夹,点击右上角【+Add files】-【Tool upload】上传数据(图3-1):

图3-1 文件上传步骤一 点击【Upload】浏览并选择所需文件(图3-2),上传完成后文件会在目标文件夹中显示(如首次上传,则需点击【Install and start transport client】安装所需工具):
3.2.2 步骤二:构建参考基因组(可选)
点击导航栏【Workflow】进入流程分析页面,在搜索框输入scRNA-seq-build-index,点击【Run】(图3-3)

图3-3 构建参考基因组步骤一 选择Run workflow,输入Entity ID,点击【Next】(图3-4):

图3-4 构建参考基因组步骤二 录入参考基因组信息,完成后点击【Next】(图3-5):

图3-5 构建参考基因组步骤三
参考基因组信息录入参数说明:
refName:参考基因组的物种名称,用于报告展示;
GTF:基因组注释GTF文件,其染色体名称需要排序并且要与FASTA文件一致,不支持压缩格式;
chrM:线粒体名称;
FASTA:基因组FASTA文件,其染色体名称需要与GTF文件一致,不支持压缩格式;
Cpu:运行所需CPU;
Mem:运行所需内存大小。
点击【Run】启动分析(图3-6):

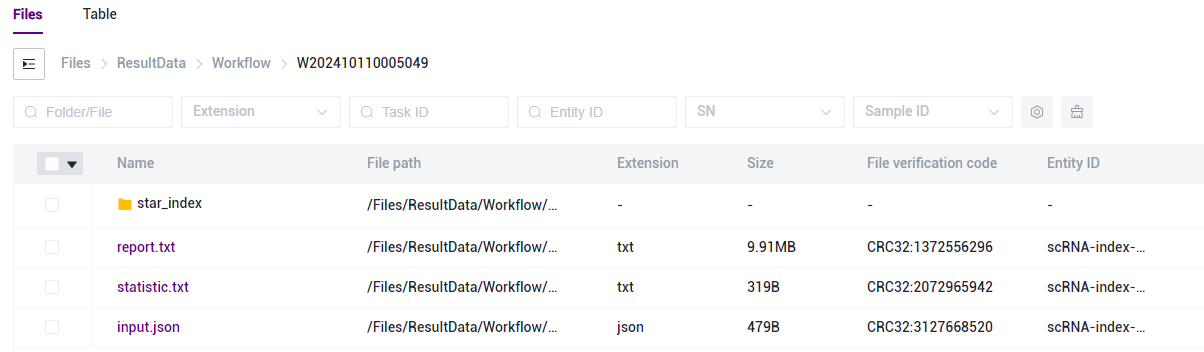
图3-6 构建参考基因组步骤四 任务完成后,Status显示为
 completed,复制 Task ID(图3-7),点击导航栏【Data】,输入Task ID 进行搜索,其中 star_index 文件将作为参考基因组文件参与scVDJ-seq分析中的5端RNA分析模块(图3-8)。
completed,复制 Task ID(图3-7),点击导航栏【Data】,输入Task ID 进行搜索,其中 star_index 文件将作为参考基因组文件参与scVDJ-seq分析中的5端RNA分析模块(图3-8)。

3.2.3 步骤三:样本信息录入
点击导航栏【Workflow】进入流程分析页面,在搜索框输入 scVDJ-seq,点击【Run】(图3-10):
图3-10 样本信息录入步骤一 选择Run workflow,输入Entity ID,点击【Next】(图3-11):
图3-11 样本信息录入步骤二 录入样本信息,完成后点击【Next】(图3-12):
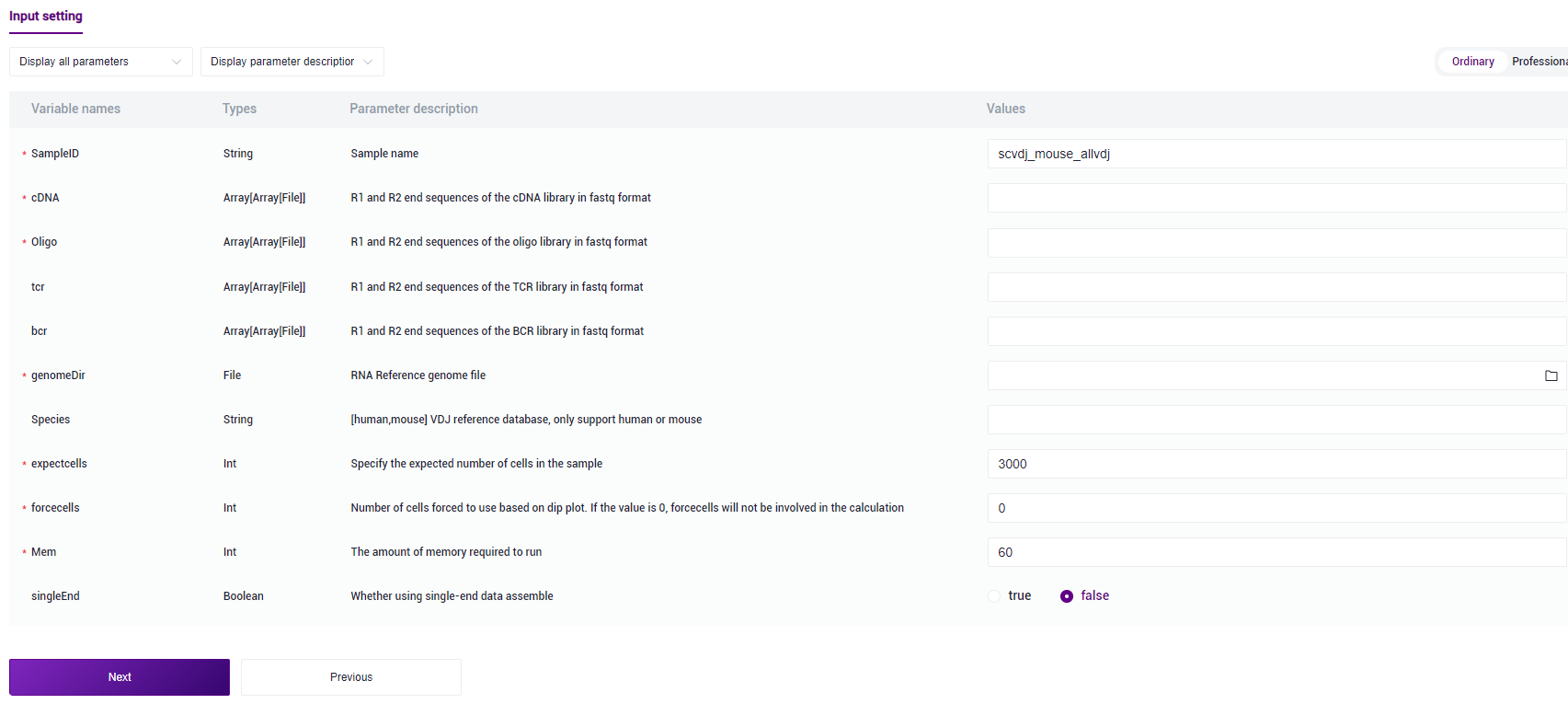
样本信息录入参数说明:
SampleID:样本名称,默认与Entity ID一致;
cDNA:cDNA文库fastq格式的R1、R2端序列;
Oligo:oligo文库fastq格式的R1、R2端序列;
tcr:选填。tcr文库fastq格式的R1、R2端序列,若不输入则不进行TCR文库的分析;
bcr:选填。bcr文库fastq格式的R1、R2端序列,若不输入则不进行BCR文库的分析;
genomeDir:5端RNA分析的参考基因组文件,如在步骤二(3.2.2 构建参考基因组)自主构建,选择Task ID文件夹内的star-index文件;
Species:VDJ分析的参考数据库,仅支持人或小鼠,只能填写human或者mouse,填写其他字符串均不进行TCR和BCR文库分析,当未输入tcr或bcr文件时,该参数不生效,可不填写;
expectcells:期望的细胞数量,可根据经验自行选择细胞数目;
forcecells:强制选取beads数目,根据骤降图强制截取 beads 数目;如为0则不参与计算保留全部细胞;
mem:运行所需内存大小,默认值为60G。运行VDJ分析所需运行内存较大,建议至少设置100G。
singleEnd:是否使用单端数据组装,默认为不使用。
3.2.4 步骤四:启动分析
点击【Run】启动分析(图3-13):
3.3 使用场景二:表格投递
操作共包括五个步骤:上传数据、构建参考基因组(可选)、下载样本模板、填写并导入样本模板、启动分析。完成样本模板导入后,可批量运行任务,当客户在看到任务状态为![]() completed 时,代表任务已完成,即可查看报告部分(详见3.4部分)。
completed 时,代表任务已完成,即可查看报告部分(详见3.4部分)。
3.3.1 步骤一:上传数据
与使用场景一(手动投递)步骤一一致(详见3.2.1步骤一:上传数据)。
3.3.2 步骤二:构建参考基因组(可选)
与使用场景一(手动投递)步骤二一致(详见3.2.2步骤二:构建参考基因组)。
3.3.3 步骤三:样本信息录入表格下载
点击导航栏【Data】,选择【Table】-【Download】(如图3-14), 点击【Data model template】,选择 scVDJ-seq 模板下载:

图3-14 scVDJ-seq 样本信息模板下载导航 打开后scVDJ-seq 样本模板Excel如图3-15:

3.3.4 步骤四:样本信息导入
- 该使用场景条件下,样本导入表格需填写工作表(图3-15)。该场景表示对已测序完成的样本数据在导入表格后,直接进入分析。
Excel注意事项:
\[1\] 导入文件路径必须在云平台已存在,若不存在文件,则不会生成任务。
\[2\] 模板中,除tcr1、tcr2、bcr1、bcr2、Species、expectcells、forcecells外的输入栏为必填项。导入数据中,必填项字段不得为空。
\[3\] Excel中的SampleID需唯一。
\[4\] Excel中不能合并单元格,单元格内容前后不能有空格或特殊字符。
\[5\] 分析样本录入(图3-16):
参数说明:
SampleID:样本名称,默认与Entity ID一致;
cDNA:cDNA文库fastq格式的R1、R2端序列;
Oligo:oligo文库fastq格式的R1、R2端序列;
tcr:选填。tcr文库fastq格式的R1、R2端序列,若不填写则不进行TCR文库的分析;
bcr:选填。bcr文库fastq格式的R1、R2端序列,若不填写则不进行BCR文库的分析;
genomeDir:5端转录组分析的参考基因组文件,如在步骤二(3.2.2 构建参考基因组)自主构建,选择Task ID文件夹内的star-index文件;
Species:VDJ分析的参考数据库,仅支持人或小鼠,只能填写human或者mouse,填写其他字符串均不进行TCR和BCR文库分析,当未输入tcr或bcr文件时,该参数不生效,可不填写;
expectcells:期望的细胞数量,可根据经验自行选择细胞数目;
forcecells:强制选取beads数目,根据骤降图强制截取 beads 数目;如为0则不参与计算保留全部细胞;
mem:运行所需内存大小,默认值为60G。若需要运行VDJ分析,所需运行内存较大,建议至少设置100G。
singleEnd:是否使用单端数据组装,默认为不使用。
" =1624x319)
配置好样本模板的分析样本录入工作表后,回到【Data】界面,点击【Table】-【+Add table】(图3-17):

图3-17 样本信息导入步骤一 点击【Click to upload/ Drop here】浏览并选择已填好样本信息的表格,点击【confirm】(图3-18),上传完成后文件会在目标文件夹中显示:
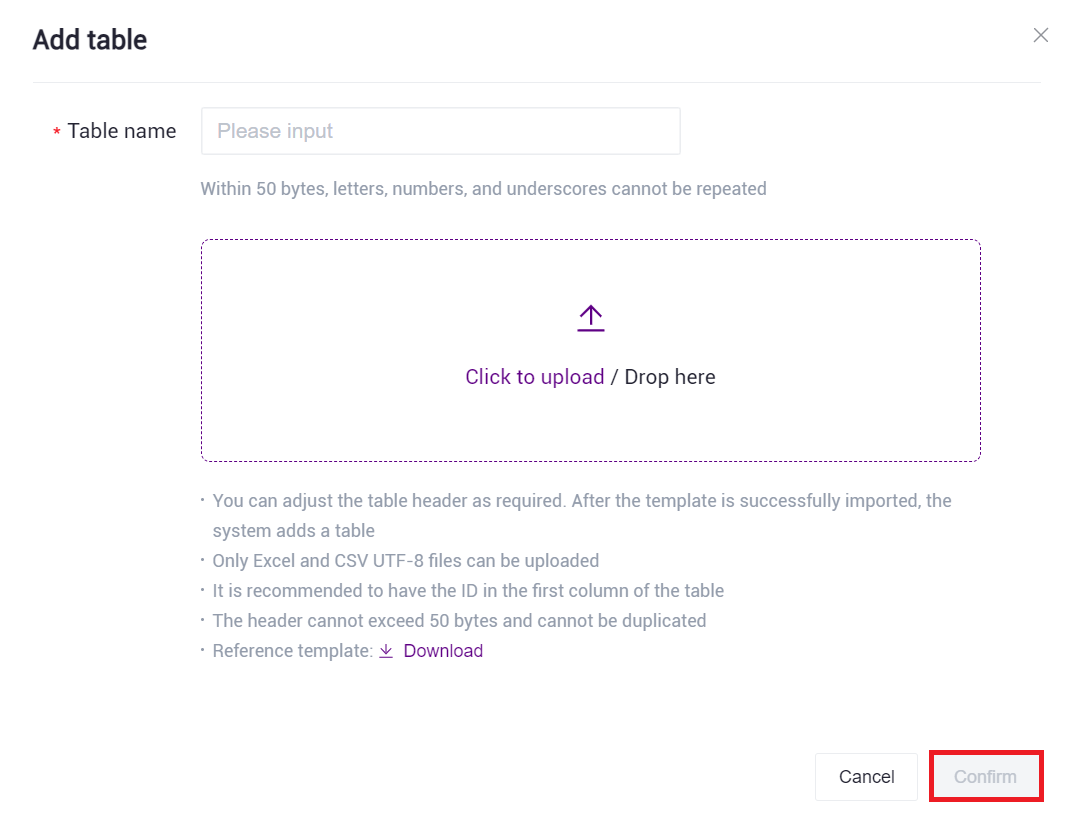
图3-18 样本信息导入步骤二 点击导航栏【Workflow】进入流程分析页面,在搜索框输入scVDJ-seq,点击【Run】(图3-19):
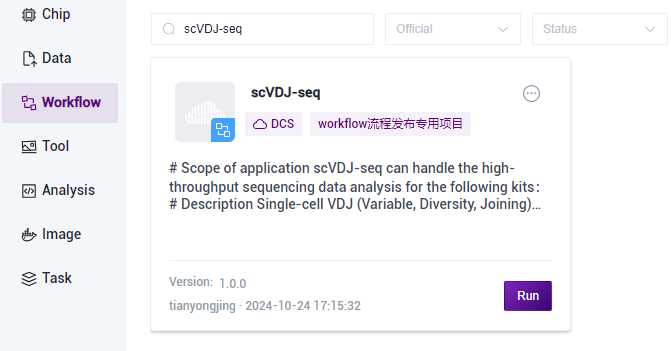
图3-19 样本信息导入步骤三 选择Run workflow(s),点击 Please select table
 处,选择在本小节3)中导入的表格,选中所需的行,点击【Next】(图3-20):
处,选择在本小节3)中导入的表格,选中所需的行,点击【Next】(图3-20):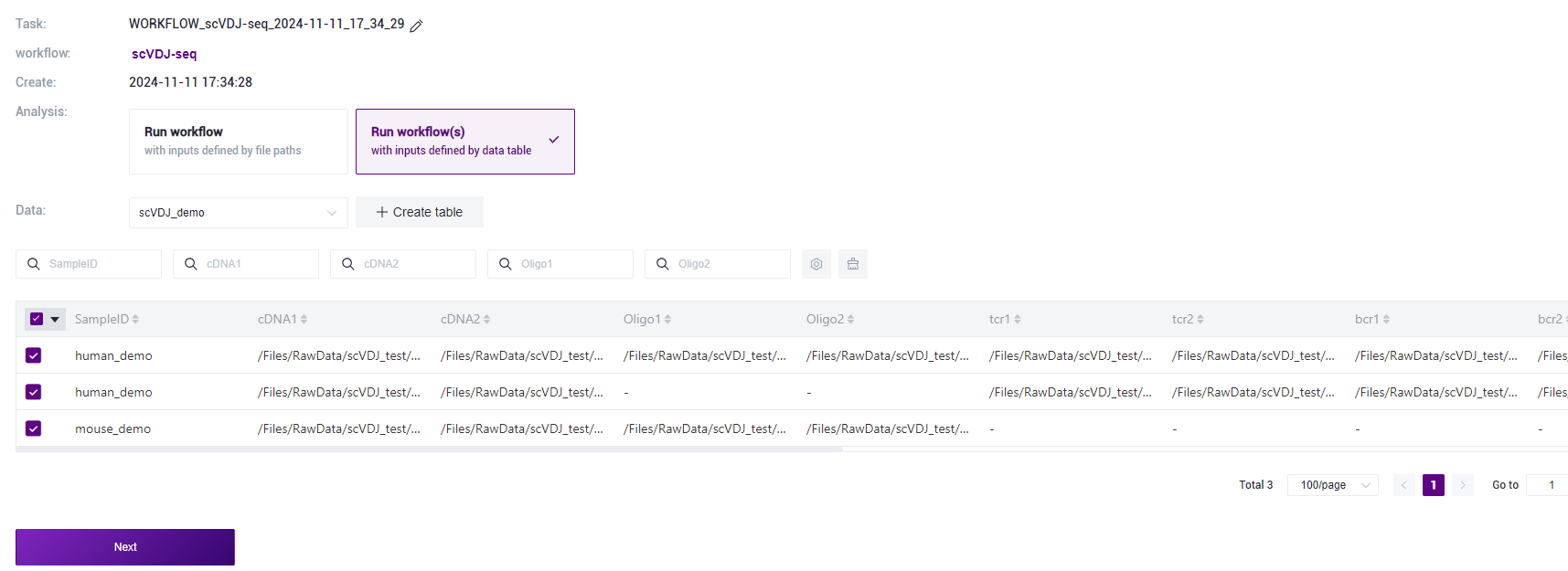
图3-20 样本信息导入步骤四 在Values处点击
 并选择对应的值,如cDNA选取{cDNA2},注意按顺序选取(如图3-21):
并选择对应的值,如cDNA选取{cDNA2},注意按顺序选取(如图3-21):
图3-21 样本信息导入步骤五 录入样本信息,完成后点击【Next】,确保参数设置无误(如图3-22):
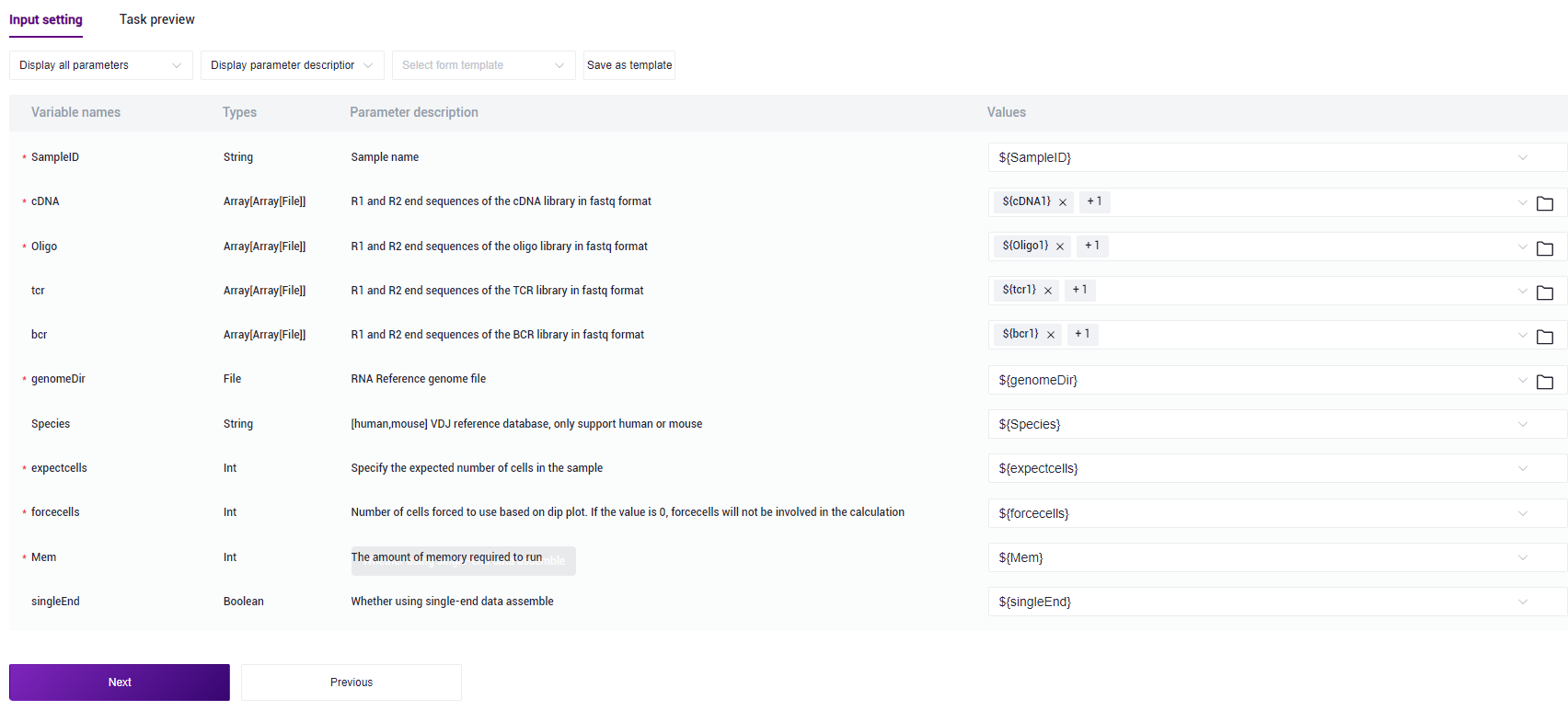
3.3.5 步骤五:启动分析
- 点击【Run】启动分析(图3-23):
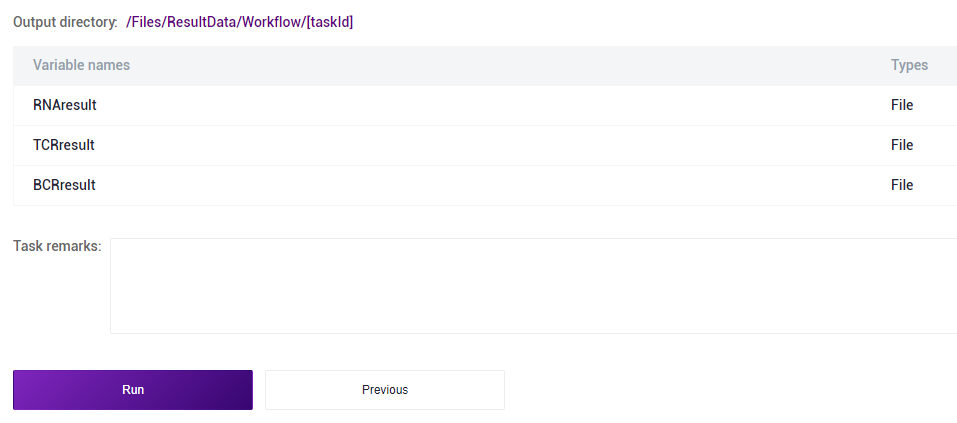
3.4 报告查看及结果文件下载
3.4.1 报告查看
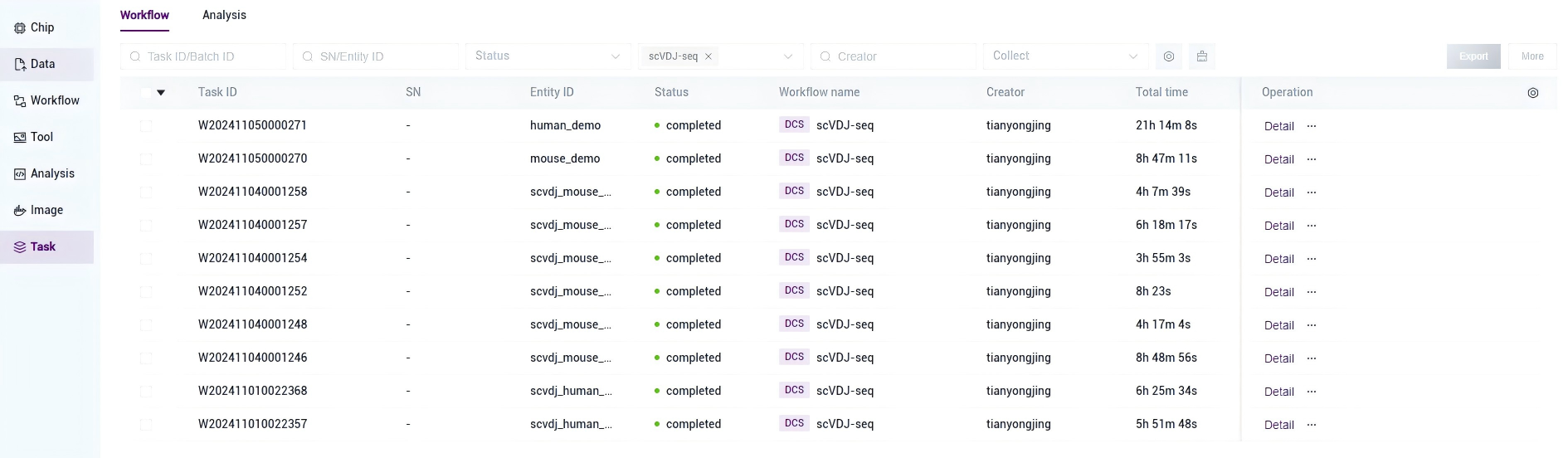
- 点击导航栏【Task】,当任务状态显示为completed时,代表任务已完成,点击【Detail】即可查看结果部分(如图3-24):
3.4.2 报告下载
点击导航栏【Data】,进入数据管理页面,根据任务的Task ID进行搜索,点击进入Task ID文件夹(如图3-25):
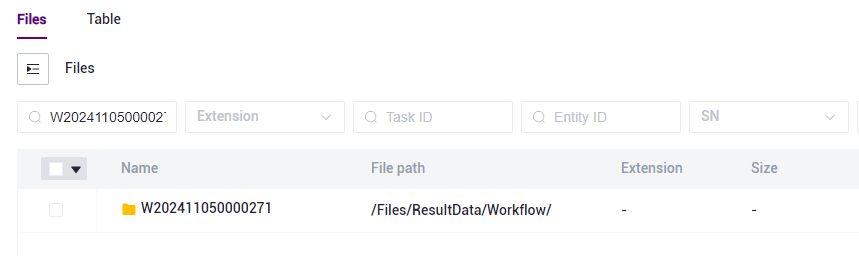
图3-25 报告下载步骤一 如果需要RNA或TCR或BCR分析对应的报告,需要分别点击进入 RNA或TCR或BCR 文件夹(如图3-26):
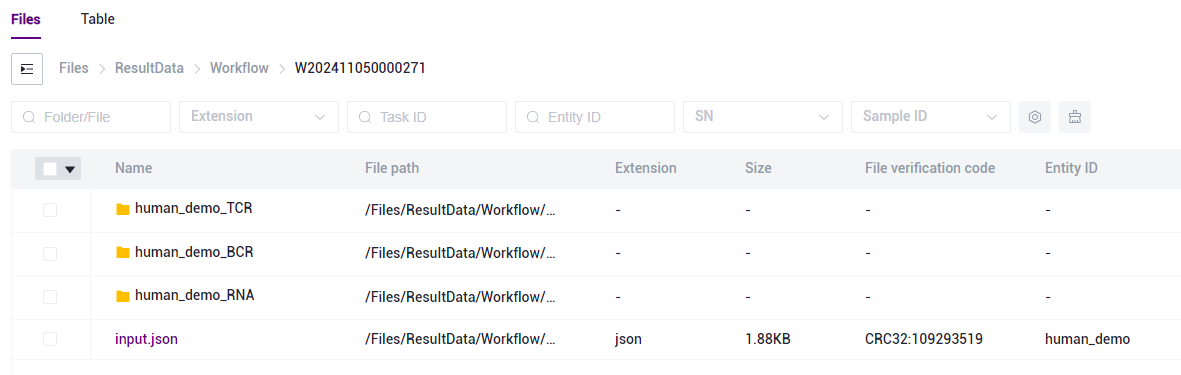
图3-26 报告下载步骤二 点击进入 output文件夹(如图3-26):
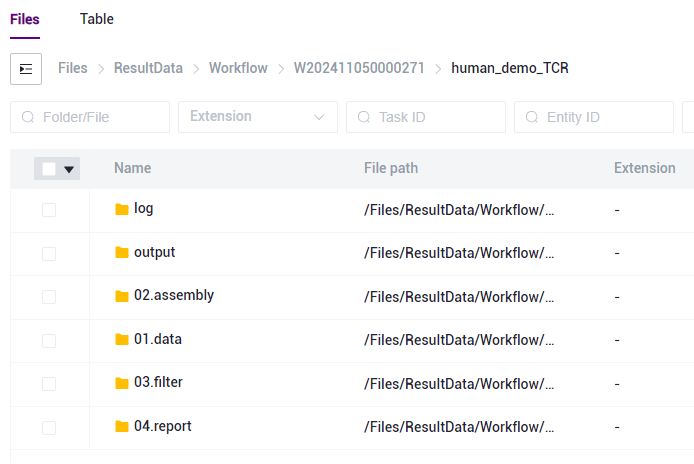
图3-26 报告下载步骤二 选中 report.html 文件,点击【Download】-【Raysync download】(如图3-27):
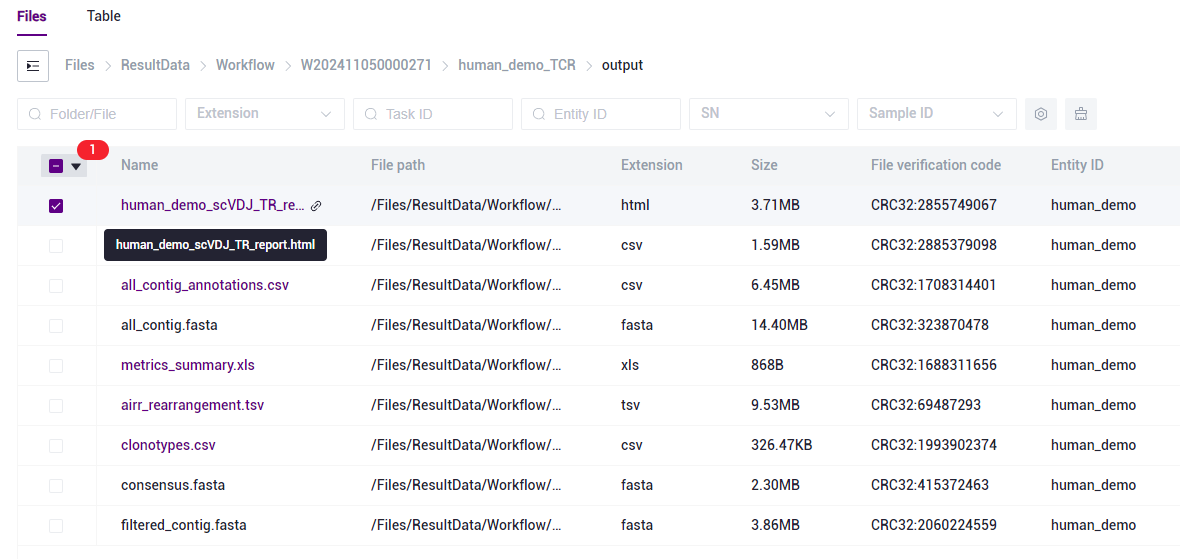
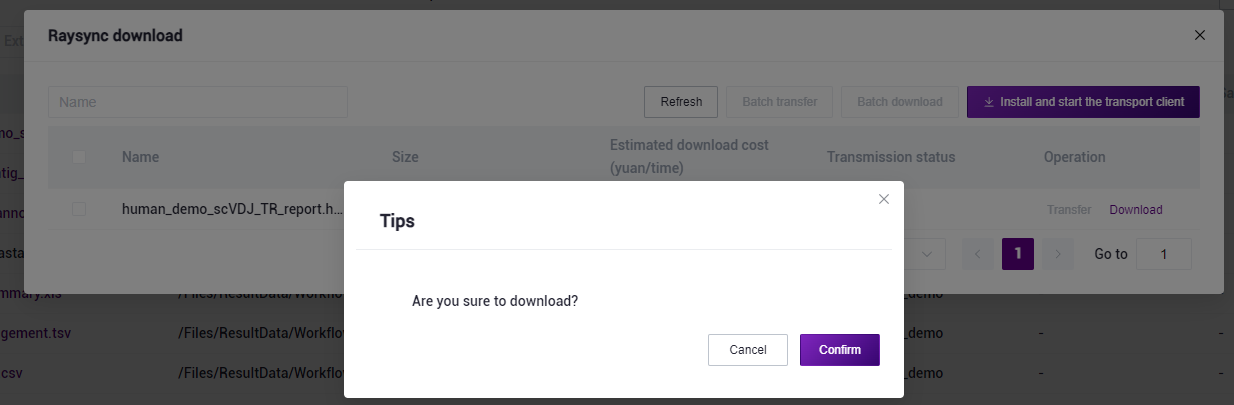
- 点击【Download】-【Confirm】,选择目标目录并下载报告(如图3-28):
第四章 结果展示
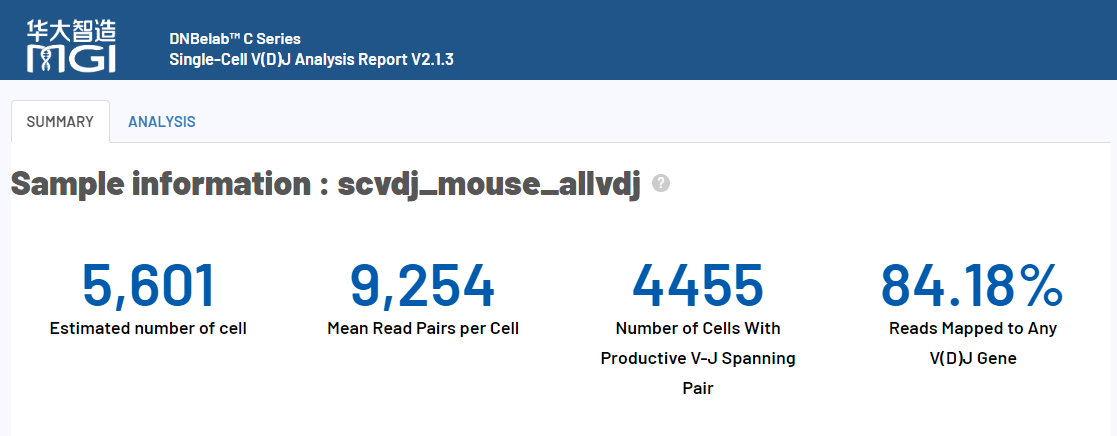
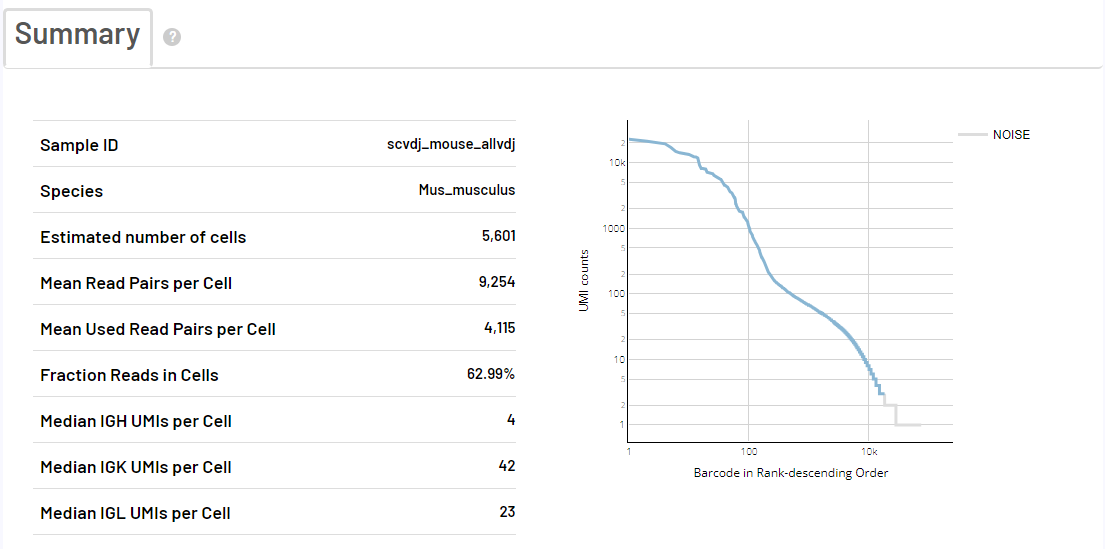
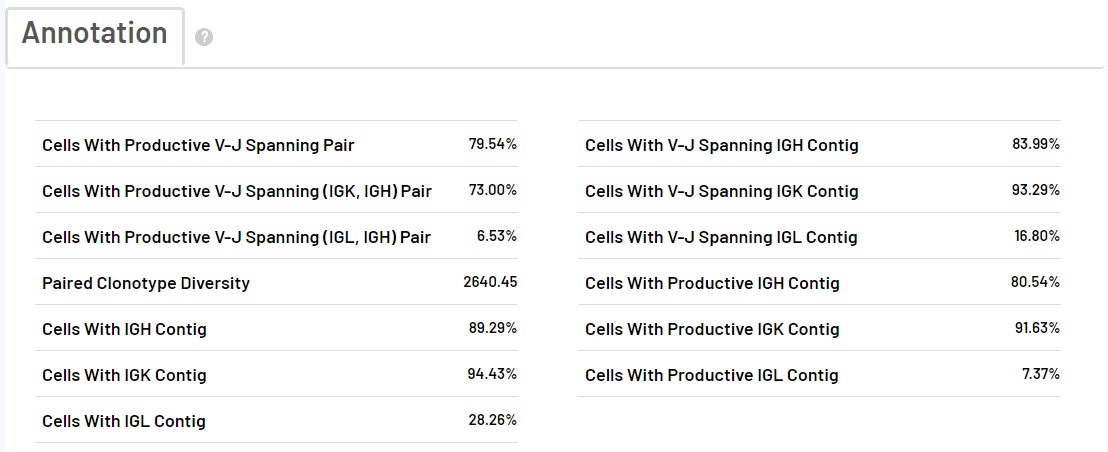
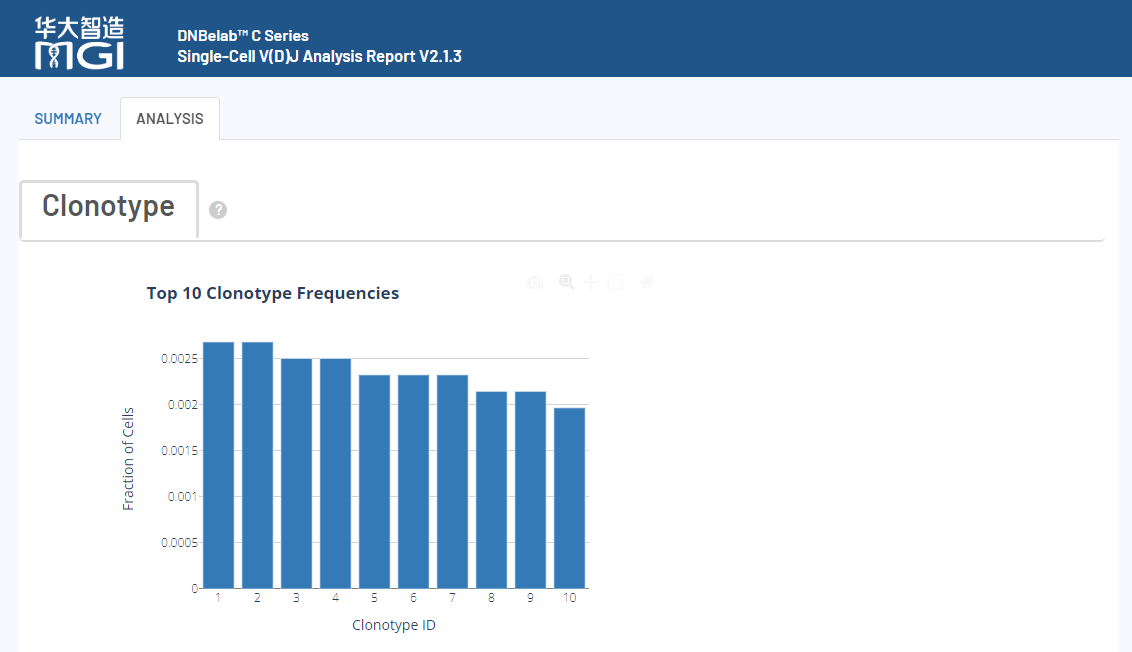
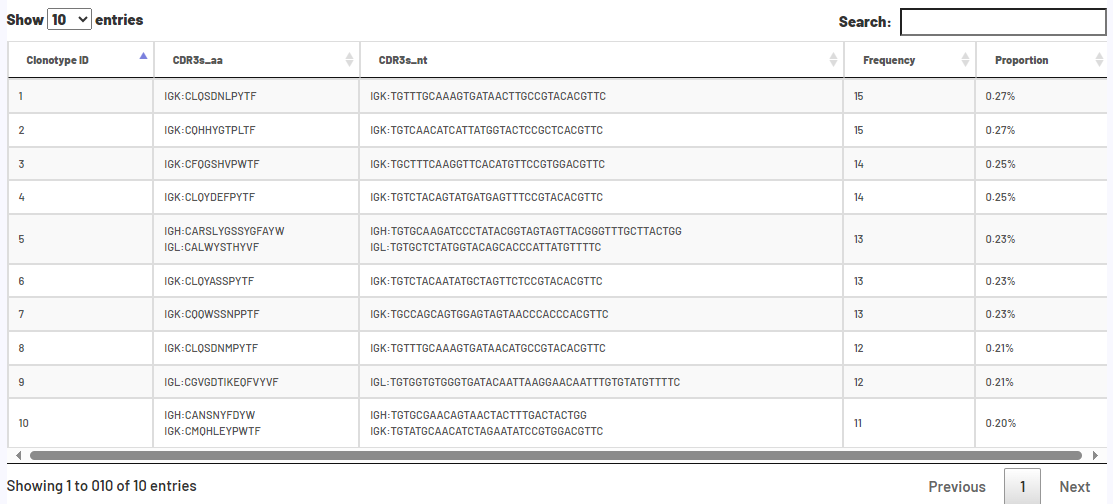
4.1 scVDJ-seq样本报告展示
5端单细胞转录组的报告与scRNA-seq_v3流程的报告相同,下面以BCR分析为例,仅展示VDJ分析的报告。