Bulk RNA-seq 用户手册
第一章 产品信息
产品描述
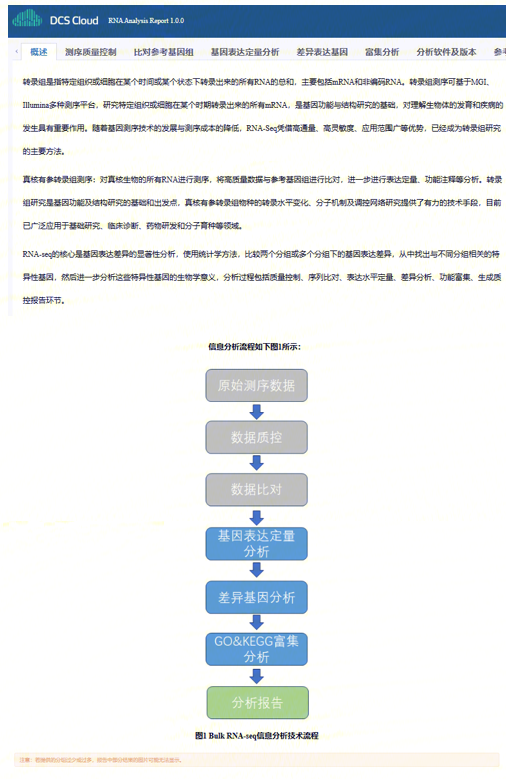
转录组是指特定组织或细胞在某个时间或某个状态下转录出来的所有RNA的总和,主要包括mRNA和非编码RNA。转录组测序可基于MGI、Illumina多种测序平台,研究特定组织或细胞在某个时期转录出来的所有mRNA,是基因功能与结构研究的基础,对理解生物体的发育和疾病的发生具有重要作用。随着基因测序技术的发展与测序成本的降低,RNA-Seq凭借高通量、高灵敏度、应用范围广等优势,已经成为转录组研究的主要方法。
真核有参转录组测序分析流程(以下简称BulkRNA-seq)是对真核生物的所有RNA进行测序,将高质量数据与参考基因组进行比对,进一步进行表达定量、功能注释等分析的流程。转录组研究是基因功能及结构研究的基础和出发点,真核有参转录组为物种的转录水平变化、分子机制及调控网络研究提供了有力的技术手段,目前已广泛应用于基础研究、临床诊断、药物研发和分子育种等领域。
BulkRNA-seq的核心是基因表达差异的显著性分析,使用统计学方法,比较两个分组或多个分组下的基因表达差异,从中找出与不同分组相关的特异性基因,然后进一步分析这些特异性基因的生物学意义,分析过程包括质量控制、序列比对、表达水平定量、差异分析、功能富集、生成质控报告环节。通过用户图形化界面进行样本输入及报告输出的全流程管理,使用方法简单,且任务支持并行化,缩短分析周期,达到快速、高效交付的目的。
注意事项
当前流程支持MGI和Illumina多种测序平台产出的测序数据。
支持PE及SE数据的流程投递。
当前版本功能富集分析仅支持人和鼠两个物种。
当前流程最新版本为:V1.0.0。
第二章 产品介绍
分析流程图
BulkRNA-seq分析流程是基于DCS云平台系统开发的一款自动分析流程,其中包括质量控制、序列比对、表达水平定量、差异分析、功能富集以及报告生成:
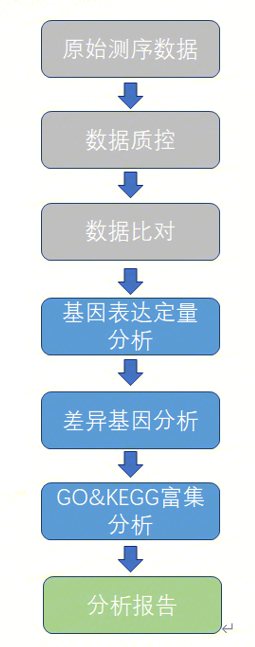
质量控制
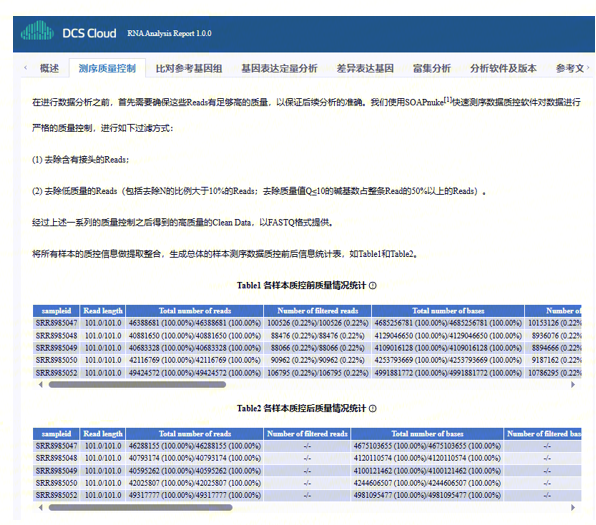
使用SOAPnuke对数据进行严格的质量控制,输出质控前后测序质量情况统计信息,过滤后得到的clean data用于后续分析。
序列比对
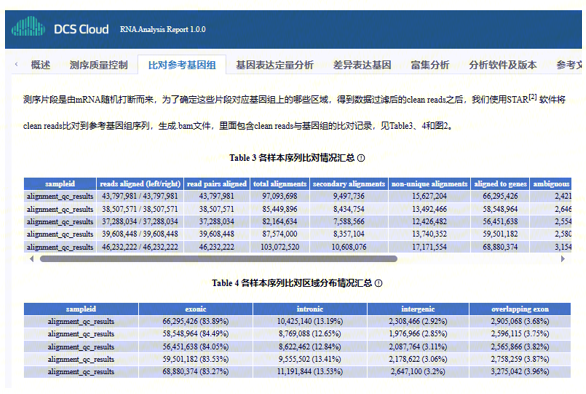
使用STAR软件将clean reads比对到参考基因组序列,生成bam文件和比对结果统计。使用Qualimap2评估比对结果。
表达水平定量
用subRead软件包中的featureCounts软件计算gene的count数,其关键计算参数为: -p -t exon -g gene_id。这里的count指的是fragment count, 即对于双端测序来说一对reads是按照一个整体(fragment)来计数的。
差异分析
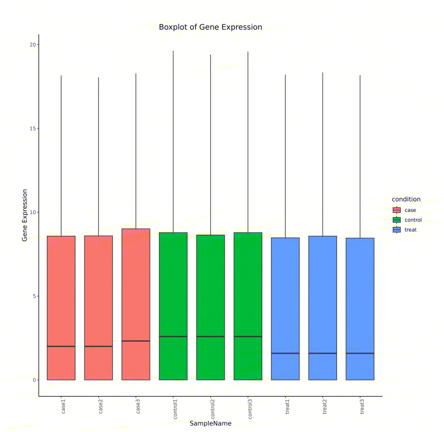
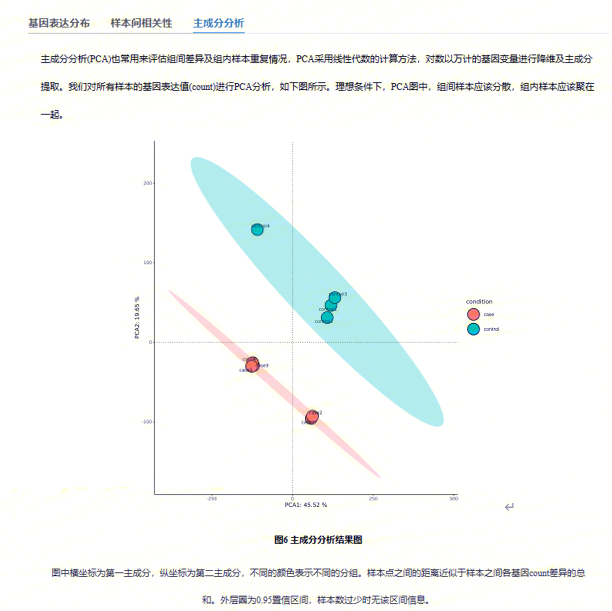
使用DESeq2计算校正后的表达量,进行样本间相关性分析和主成分分析,用于评估组间差异及组内样本重复情况,并对表达数据进行统计学分析,进而筛选不同样本之间显著差异的基因。
功能富集分析
使用clusterProfiler对显著差异基因进行KEGG通路分析和GO富集分析。
报告生成
综合分析结果,整理汇总成HTML报告。
第三章 使用说明书
BulkRNA-seq分析流程通过DCS云平台系统进行样本输入及报告输出的全流程管理。下面具体介绍基于DCS云平台系统使用BulkRNA-seq分析流程的操作指南。
指南概述
概述
本章介绍如何使用BulkRNA-seq分析流程进行分析。在使用之前,请认真阅读并理解其中内容,保证能够正确使用BulkRNA-seq分析流程。
使用场景一:手动投递
操作共包括四个步骤:上传数据、构建参考基因组(可选)、样本信息录入、启动分析。完成样本信息录入后,运行任务,当客户在看到任务状态为completed 时,代表任务已完成,即可查看报告部分(详见3.4部分)。
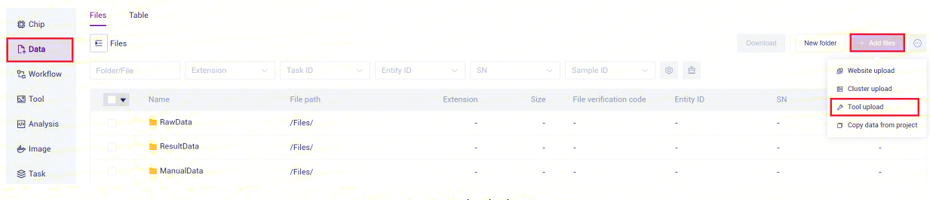
步骤一:上传数据
- 点击导航栏【Data】,进入数据管理页面,进入目标文件夹,点击右上角【+Add files】-【Tool upload】上传数据(图3-1):
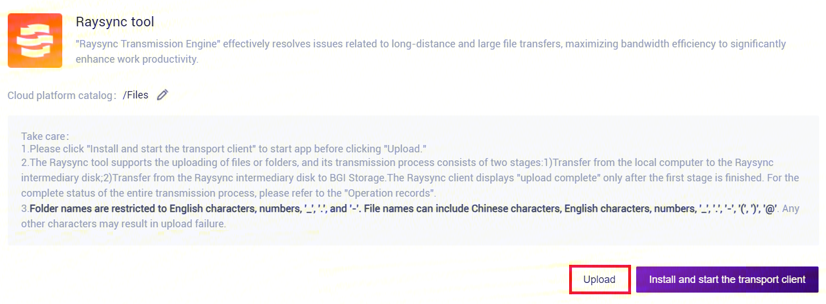
- 点击【Upload】浏览并选择所需文件(图3-2),上传完成后文件会在目标文件夹中显示(如首次上传,则需点击【Install and start transport client】安装所需工具):
步骤二:构建参考基因组(可选)
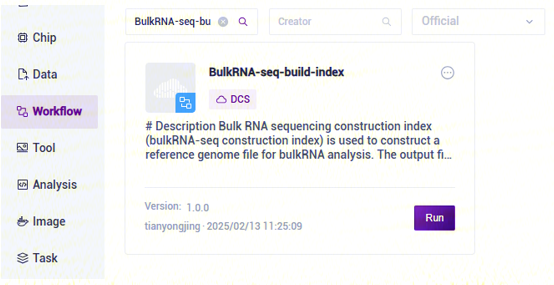
- 点击导航栏【Workflow】进入流程分析页面,在搜索框输入BulkRNA-seq-build-index,点击【Run】(图3-3):
- 选择Run workflow,输入Entity ID,点击【Next】(图3-4):
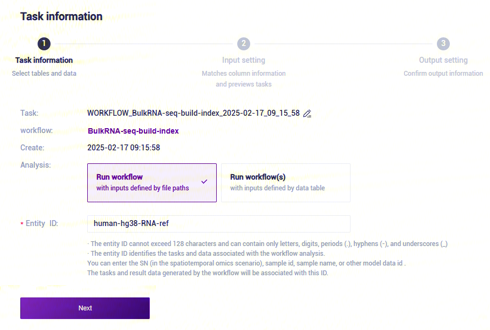
- 录入参考基因组信息,完成后点击【Next】(图3-5):

参考基因组信息录入参数说明:
GTF:基因组注释GTF文件,其染色体名称需要排序并且要与FASTA文件一致,不支持压缩格式;
FASTA:基因组FASTA文件,其染色体名称需要与GTF文件一致,不支持压缩格式;
- 点击【Run】启动分析(图3-6):
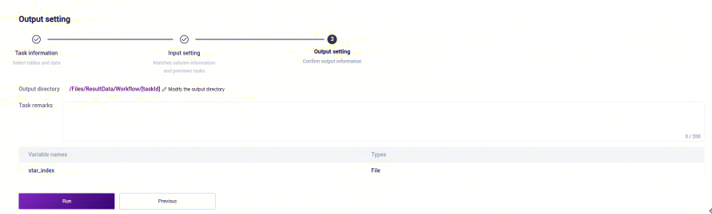
- 任务完成后,Status显示为completed,复制Task ID(图3-7),点击导航栏【Data】,输入Task ID 进行搜索,其中 star_index 文件作为参考基因组文件夹(图3-8)。


步骤三:样本信息录入
- 点击导航栏【Workflow】进入流程分析页面,在搜索框输入 BulkRNA-seq,点击【Run】(图3-10):
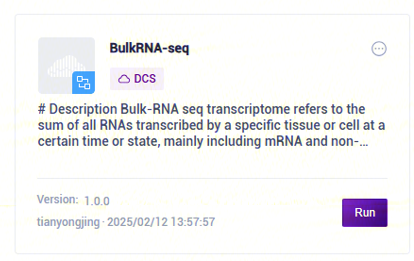
- 选择Run workflow,输入Entity ID,点击【Next】(图3-11):
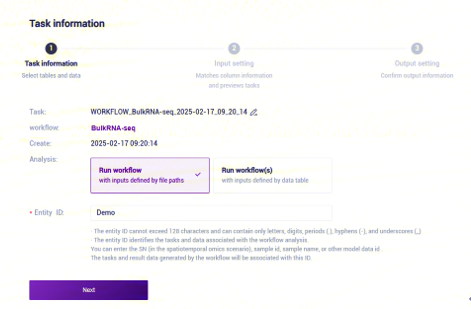
- 录入样本信息,完成后点击【Next】(图3-12):
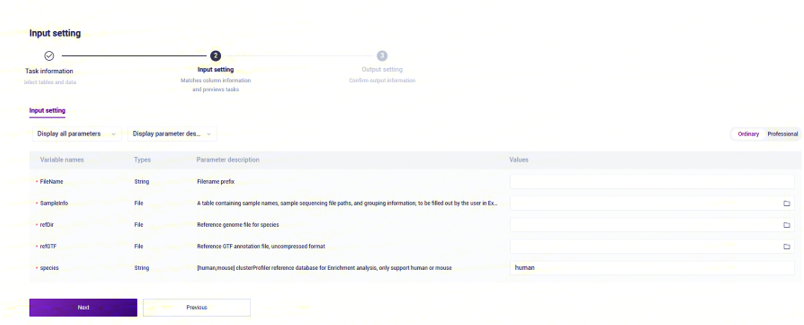
样本信息录入参数说明:
FileName:输出文件名前缀;
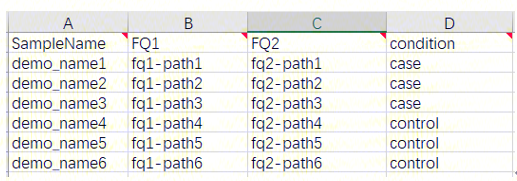
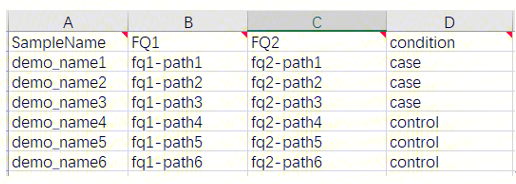
SampleInfo:包含样本名(SampleName)、样本测序文件(FQ1和FQ2)和分组信息(condition)的表格; 由用户在excel中填写,保存为csv格式,上传至数据管理;
其中,样本名不可重复,由英文字母、数字和下划线组成;
样本测序文件路径要求是真实绝对路径,而非虚拟和相对路径,双端测序数据分别填写FQ1和FQ2,单端测序数据仅填写FQ1;
DCS云平台真实绝对路径如下图:

鼠标悬浮于文件旁边的🔗符号,复制红框中的真实文件路径,输入至表格中的FQ1或FQ2
分组建议存在生物学重复,由英文字母、数字和下划线组成;
refDir:转录组分析的参考基因组文件,如在步骤二(3.2.2 构建参考基因组)自主构建,选择Task ID文件夹内的star_index文件;
refGTF:基因组注释GTF文件;
species:富集分析的参考数据库,仅支持人或小鼠,只能填写human或者mouse,填写其他字符串均不进行富集分析。
步骤四:启动分析
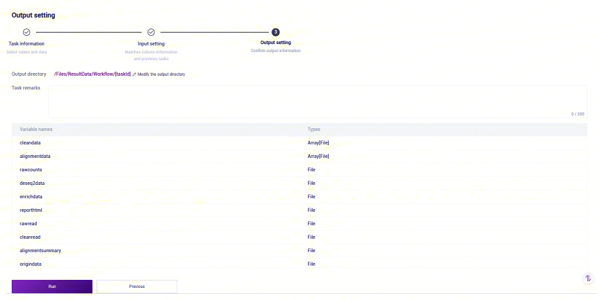
点击【Run】启动分析(图3-13):
使用场景二:表格投递
操作共包括五个步骤:上传数据、构建参考基因组(可选)、下载样本模板、填写并导入样本模板、启动分析。完成样本模板导入后,可批量运行任务,当客户在看到任务状态为completed 时,代表任务已完成,即可查看报告部分(详见3.4部分)。
步骤一:上传数据
与使用场景一(手动投递)步骤一一致(详见3.2.1步骤一:上传数据)。
步骤二:构建参考基因组(可选)
与使用场景一(手动投递)步骤二一致(详见3.2.2步骤二:构建参考基因组)。
步骤三:样本信息录入表格下载
- 点击导航栏【Data】,选择【Table】-【Download】(如图3-14), 点击【Workflow template】,选择 BulkRNA-seq 模板下载:
- 打开后BulkRNA-seq样本模板Excel如图3-15:

步骤四:样本信息导入
- 该使用场景条件下,样本导入表格需填写工作表(图3-15)。该场景表示对已测序完成的样本数据在导入表格后,直接进入分析。
注意事项:
[1] 导入文件路径必须在云平台已存在,若不存在文件,则不会生成任务。
[2] 模板中所有参数均为必填项(除单端测序数据FQ2可不填)。导入数据中,必填项字段不得为空。
[3] Excel中的EntityID需唯一。
[4] Excel中不能合并单元格,单元格内容前后不能有空格或特殊字符。
[5] 分析样本录入(图3-16):
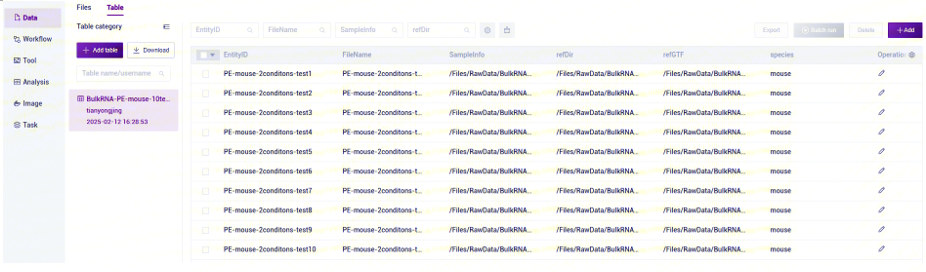
EntityID:为流程分析过程中关联任务和数据的标识ID,可以填写sampleid等分析所需的真实ID,是表格投递必须的列 用来判断多行数据是否合并为一个样本分析,需特别注意同一个EntityID只能对应一个任务;
FileName:生成文件名前缀;
SampleInfo:包含样本名(SampleName)、样本测序文件(FQ1和FQ2)和分组信息(condition)的表格; 由用户在excel中填写,保存为csv格式,上传至数据管理;
其中,样本名不可重复,由英文字母、数字和下划线组成;
样本测序文件路径要求是真实绝对路径,而非虚拟和相对路径,双端测序数据分别填写FQ1和FQ2,单端测序数据仅填写FQ1;
DCS云平台真实绝对路径如下图:

鼠标悬浮于文件旁边的🔗符号,复制红框中的真实文件路径,输入至表格中的FQ1或FQ2
分组建议存在生物学重复,由英文字母、数字和下划线组成;
refDir:转录组分析的参考基因组文件,如在步骤二(3.2.2 构建参考基因组)自主构建,选择Task ID文件夹内的star_index文件;
Species:富集分析的参考数据库,仅支持人或小鼠,只能填写human或者mouse,填写其他字符串均不进行富集分析。

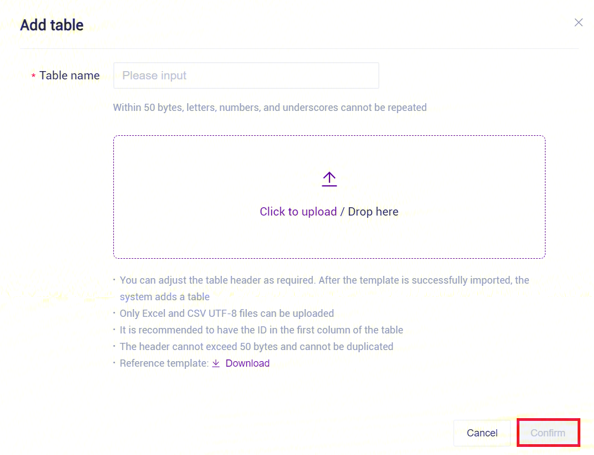
- 配置好样本模板的分析样本录入工作表后,回到【Data】界面,点击【Table】-【+Add table】(图3-17):
- 点击【Click to upload/ Drop here】浏览并选择已填好样本信息的表格,点击【confirm】(图3-18),上传完成后文件会在目标文件夹中显示:
- 点击导航栏【Workflow】进入流程分析页面,在搜索框输入**BulkRNA-seq****,**点击【Run】(图3-19):
- 选择Run workflow(s),点击 Please select table处,选择在本小节3)中导入的表格,选中所需的行,点击【Next】(图3-20):
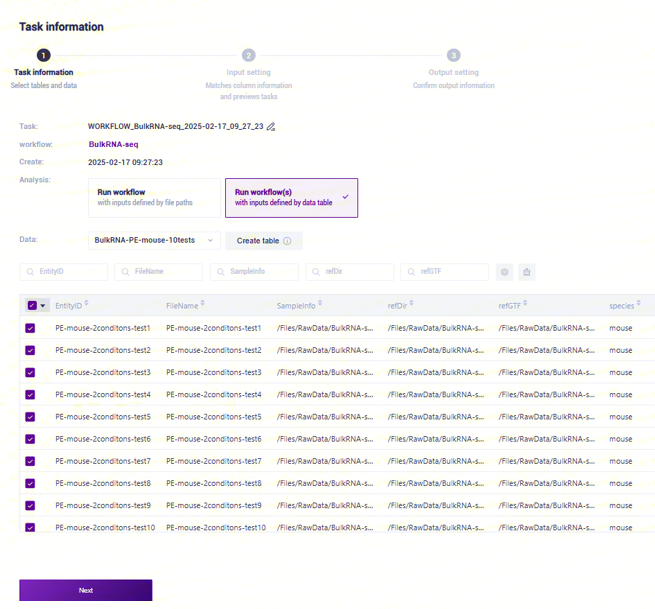
- Values一般会自动填充,仅需要检查填充是否正确,若需修改则在Values处点击并选择对应的值(如图3-21):
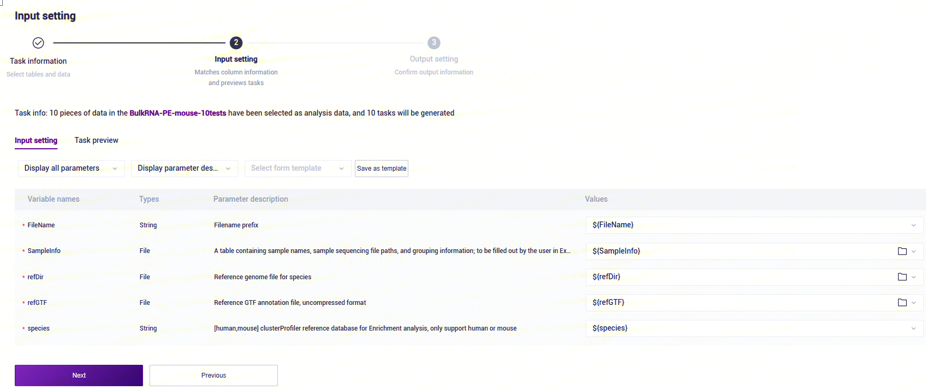
步骤五:启动分析
点击【Run】启动分析(图3-23):
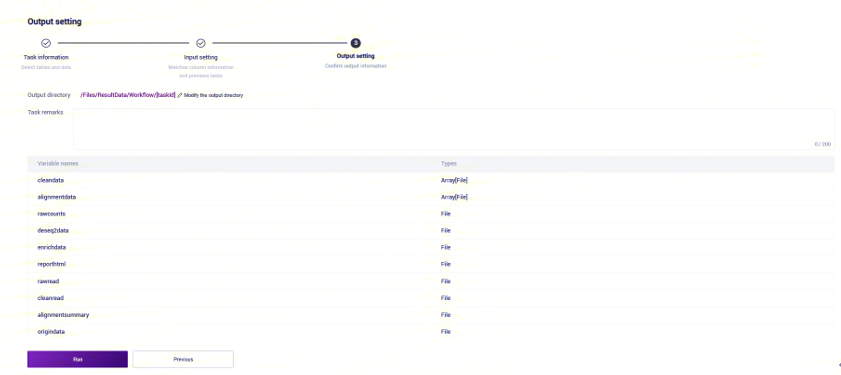
报告查看及结果文件下载
报告查看
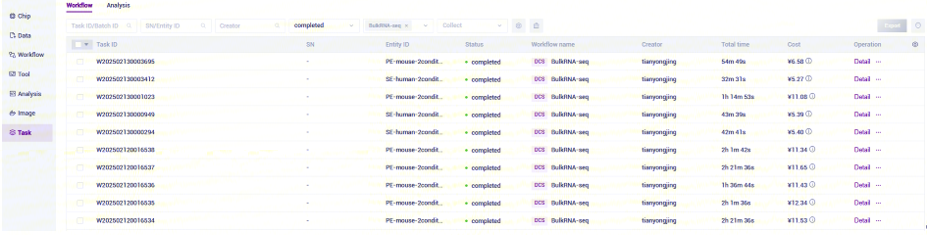
点击导航栏【Task】,当任务状态显示为completed时,代表任务已完成,点击【Detail】即可查看结果部分(如图3-24):
报告下载
- 点击导航栏【Data】,进入数据管理页面,根据任务的Task ID进行搜索,点击进入Task ID文件夹(如图3-25):
- 点击进入06.report文件夹(如图3-26):

- 选中***report.html** 文件,点击【Download】-【Web download】(如图3-27):
第四章 结果展示
BulkRNA-seq样本报告展示


 与参考文献信息")
与参考文献信息")